





I. Introduction▲
Afin de gérer une plus grande sollicitation (par exemple : calcul intensif ou afflux important de trafic réseau), une architecture matérielle doit pouvoir évoluer : on parle de scalabilité. On distingue alors deux types de scalabilités. La première dite scalabilité horizontale consiste à ajouter de nouveaux serveurs à son architecture, c'est le cas d'Apache Hadoop. La seconde dite scalabilité verticale consiste à faire évoluer le matériel d'un ordinateur donné (le nombre de cœurs d'un processeur par exemple).
La scalabilité verticale apporte des gains de performance, mais se heurte à la limite physique du matériel. Le nombre de cœurs, la taille mémoire et la taille du disque dur ne sont pas extensibles sur de grandes échelles. C'est dans cette optique qu'Apache Hadoop a été conçu : stocker et traiter dans une architecture matérielle à scalabilité horizontale de grands volumes d'informations.
Cet article se propose de réaliser une expérimentation entre ces deux types d'architecture matérielle via une solution à base d'Apache Hadoop pour la scalabilité horizontale et une solution à base de programme Java ad hoc pour la scalabilité verticale. L'expérimentation s'appuiera sur le programme de compte de mots sur un fichier d'une taille de 50 Go. Comme ce programme existe déjà comme exemple de job MapReduce, une version en Java multithread a été développée à cette occasion. L'expérimentation vise à identifier également dans l'architecture matérielle quels sont les facteurs limitants, c'est-à-dire les éléments matériels qui sont susceptibles de ralentir l'exécution des programmes (sollicitations excessives du CPU et/ou des disques durs).
Dans une première partie, nous présenterons les étapes de mise en place pour installer un cluster multinœud en nous basant sur la distribution CDH 5 fournie par la société Cloudera. Dans une deuxième partie, nous détaillerons tous les outils utilisés pour réaliser nos expérimentations. Notamment, nous décrirons le code du programme Java ad hoc et les outils de supervision qui vont générer les métriques pour notre expérimentation. Enfin dans une dernière partie, nous donnerons une conclusion à cet article.
II. Caractéristiques techniques du cluster et installation du système d'exploitation▲
Pour la mise en place du cluster, nous nous appuierons jusqu'à six machines virtuelles dont une sera dédiée pour le nœud NameNode/DataNode (contient également tous les services d'administration) et les cinq autres pour les nœuds DataNode simples.
La machine physique utilisée est un serveur Rack Dell PowerEdge R420 équipé d'un processeur Intel Xeon E5-2440 V2 1.90GHz 8 CPU (16 vCPU), de 65 Go de mémoire et de quatre disques durs (SATA 7200 Tpm) d'une capacité de 2 To chacun. La fréquence du processeur n'est pas exceptionnelle, je vous l'accorde, mais il suffira à réaliser mes expérimentations.
Pour la virtualisation, un Xen Server 6.2 a été installé en s'appuyant sur la distribution fournie par Citrix.
Chaque machine virtualisée est un Linux Ubuntu Server 12.04 LTS, avec 8 Go de mémoire, 500 Go de disque et 2 vCPU. L'installation ne requiert pas de configuration particulière hormis l'ajout des packages pour le support d'un serveur SSH et les drivers spécifiques à Xen (via le disque ISO xs-tools.iso). Le nom de l'utilisateur (login) et le mot de passe utilisés après installation sont hadoopmanager.
Pour installer le système d'exploitation Linux sur les six machines virtuelles, nous l'avons simplement installé sur une machine virtuelle puis nous l'avons dupliqué cinq fois en faisant attention de modifier :
- l'adresse MAC de la carte réseau de chaque machine virtuelle (les adresses IP sont distribuées automatiquement en fonction des adresses MAC) ;
- le nom de la machine (hostname) ;
- désactiver le SWAP disque pour de meilleures performances (ajouter la ligne vm.swappiness=0 à la fin du fichier /etc/sysctl.conf). Pour effectuer un changement immédiat sans redémarrer la machine virtuelle exécuter la ligne de commande suivante : $ sysctl vm.swappiness=0.
À la fin de l'installation et de la configuration, voici la configuration réseau de chaque machine virtuelle :
- Machine 1 (NameNode/DataNode) : IP 193.55.163.212, HostName s-virtual-machine1 ;
- Machine 2 (DataNode) : IP 193.55.163.213, HostName s-virtual-machine2 ;
- Machine 3 (DataNode) : IP 193.55.163.214, HostName s-virtual-machine3 ;
- Machine 4 (DataNode) : IP 193.55.163.215, HostName s-virtual-machine4 ;
- Machine 5 (DataNode) : IP 193.55.163.216, HostName s-virtual-machine5 ;
- Machine 6 (DataNode) : IP 193.55.163.217, HostName s-virtual-machine6.
Pour vérifier que l'installation des six machines virtuelles fonctionne, connectez-vous en SSH sur le nœud principal Namenode/DataNode identifié par s-virtual-machine1.
$ ssh hadoopmanager@s-virtual-machine1II-A. Paramétrer le fichier /etc/hosts▲
Avant de commencer l'installation, nous allons opérer une modification sur le fichier /etc/hosts de chaque système d'exploitation de façon à ce qu'il contienne toutes les IP des autres machines du cluster. Par exemple pour la machine s-virtual-machine1, le fichier /etc/hosts devra contenir les informations suivantes :
127.0.0.1 localhost
193.55.163.212 s-virtual-machine1
193.55.163.213 s-virtual-machine2
193.55.163.214 s-virtual-machine3
193.55.163.215 s-virtual-machine4
193.55.163.216 s-virtual-machine5
193.55.163.217 s-virtual-machine6
...Pensez à supprimer la ligne 127.0.1.1 s-virtual-machine* du fichier /etc/hosts, elle peut être la cause de problèmes.
II-B. Désactiver le mot de passe du compte utilisateur hadoopmanager▲
Cloudera Manager nécessite d'exécuter des tâches d'administration sur les machines du cluster. Pour permettre cela, ajoutez la ligne suivante dans le fichier /etc/sudoers de chaque machine pour désactiver la demande de mot de passe (hadoopmanager correspond au nom de l'utilisateur de la machine virtuelle) :
hadoopmanager ALL=NOPASSWD: ALLIII. Téléchargement▲
Comme pour le précédent tutoriel, j'utiliserai la distribution fournie par la compagnie Cloudera. Nous opterons toutefois pour l'outil Cloudera Manager qui unifie via une interface graphique conviviale l'installation, la configuration et la gestion du cluster multinœud Hadoop.

Les packages d'installation avec les différentes versions pour Cloudera Manager sont disponibles à cette adresse : http://archive-primary.cloudera.com/cm5/installer/.
Lors de l'écriture de ce tutoriel, nous avons utilisé la version 5.1.2 de Cloudera Manager.
IV. Installation et configuration d'un cluster multinœud▲
IV-A. Installation Cloudera Manager▲
Cloudera Manager se présente sous la forme d'un serveur Web et d'une application cliente. Ce n'est pas l'installation d'Hadoop, il sert juste de facilitateur pour installer et administrer les modules Hadoop. C'est en gros l'outil qui va automatiser l'ensemble des packages que nous avions déjà installés lors du deuxième tutoriel, mais avec une dimension cluster. L'installation du serveur Cloudera Manager se fera sur la première machine s-virtual-machine1.
Connectez-vous en SSH sur la machine s-virtual-machine1 pour installer Cloudera Manager.
Téléchargez la version de Cloudera Manager vers le répertoire HOME de l'utilisateur hadoopmanager.
$ wget http://archive-primary.cloudera.com/cm5/installer/5.1.2/cloudera-manager-installer.binComme l'installation se fait « en ligne », les paquets installés seront issus de la dernière version disponible. Ainsi, il se peut que si vous expérimentez en suivant ce tutoriel, une version plus récente de Cloudera Manager soit installée.
Modifier les droits afin d'autoriser l'exécution puis exécuter le binaire en root.
$ chmod u+x cloudera-manager-installer.bin
$ sudo ./cloudera-manager-installer.binDifférents écrans apparaissent. Veuillez suivre les différentes propositions et accepter la licence d'utilisation.
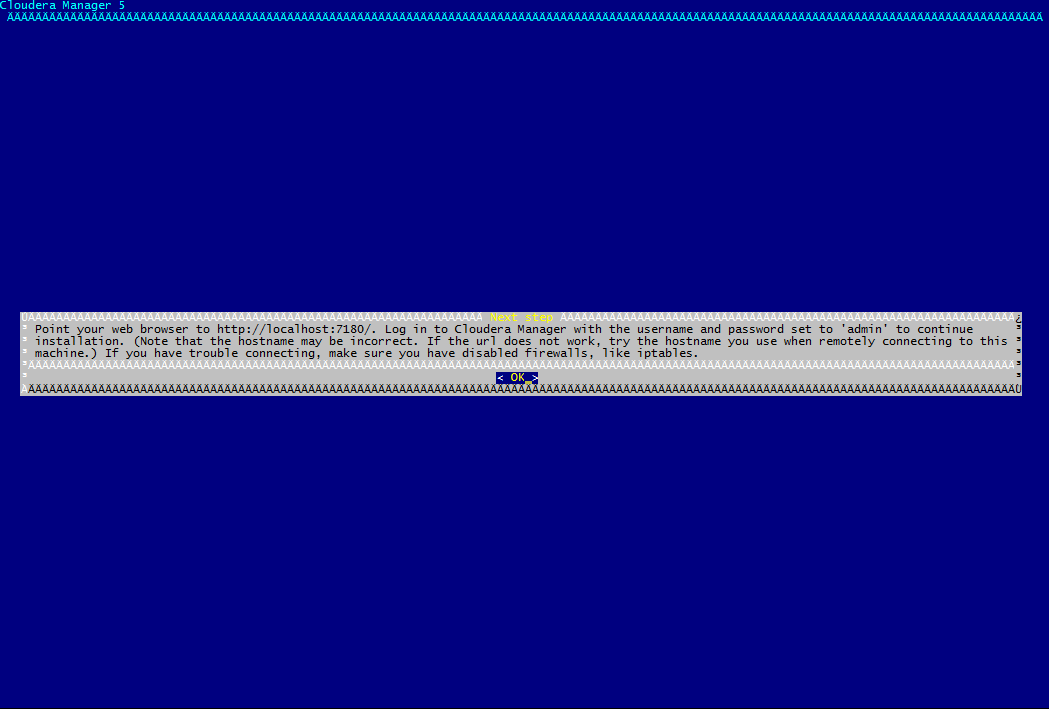
L'installation démarre et s'occupe d'installer tous les packages nécessaires. Si tout s'est bien passé, vous devriez obtenir l'écran suivant qui vous donne des indications pour accéder à Cloudera Manager.
IV-B. Installation d'un cluster trois nœuds▲
Cloudera Manager est désormais prêt à l'emploi. Nous allons pouvoir l'utiliser pour installer Hadoop sur un petit cluster de trois nœuds. Pour cela, Cloudera Manager fournit une interface Web très simpliste pour initialiser un Cluster. L'interface Web est accessible depuis l'URL (http://s-virtual-machine1:7180). L'identifiant de connexion et le mot de passe sont par défaut admin.
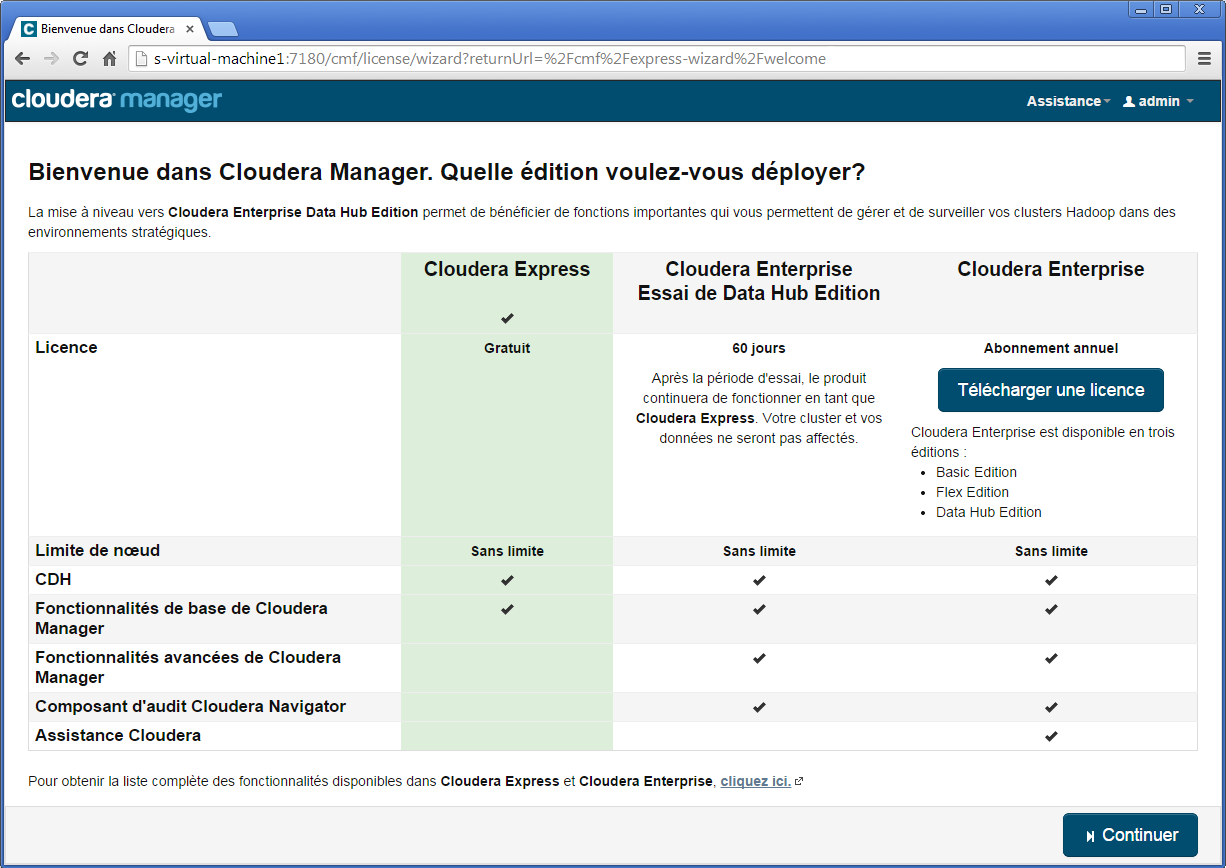
Sélectionnez l'édition Cloudera Express puis cliquez Continuer.
L'ensemble des modules Hadoop qui seront installés (Hadoop Core, HBase, ZooKeeper, Oozie, Hive, Hue…) sont détaillés sur l'écran suivant.
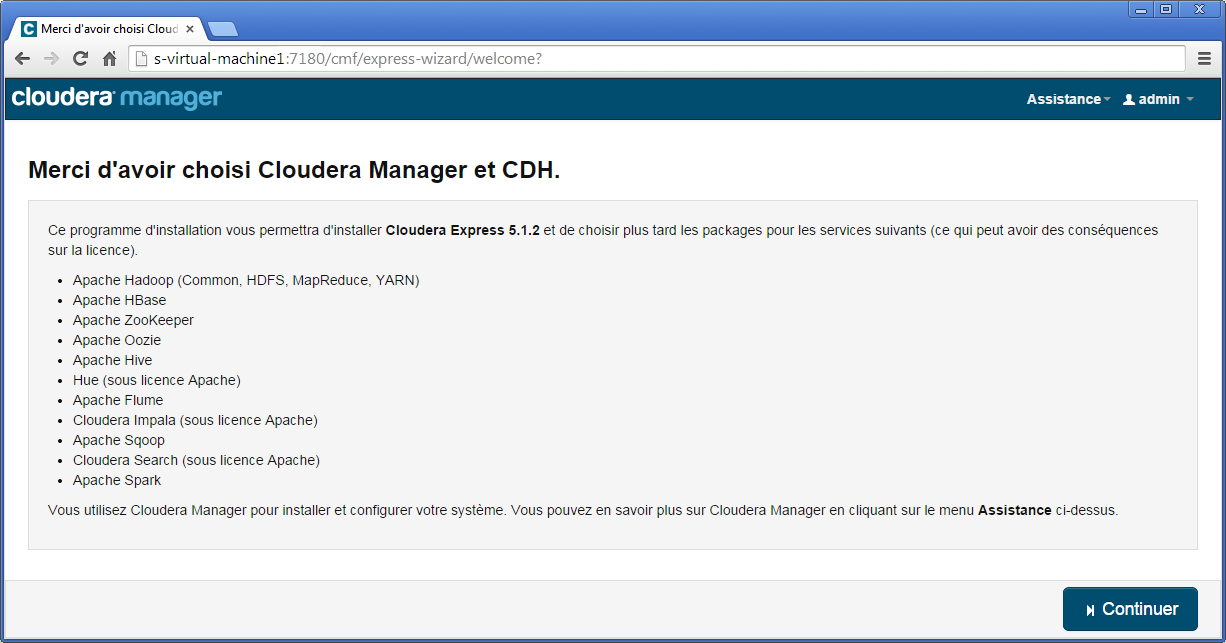
Dans le dernier écran, il vous sera demandé les machines qui feront partie du cluster. Nous débuterons avec un cluster trois nœuds. Le premier nœud est le NameNode/DataNode identifié par s-virtual-machine1 et déjà utilisé puisqu'il s'agit du nœud où est installé Cloudera Manager. Pour les deux autres, il s'agit de s-virtual-machine2 et de s-virtual-machine3.
Veuillez saisir l'adresse IP des machines dans le formulaire pour constituer une première base de machines pour notre cluster.
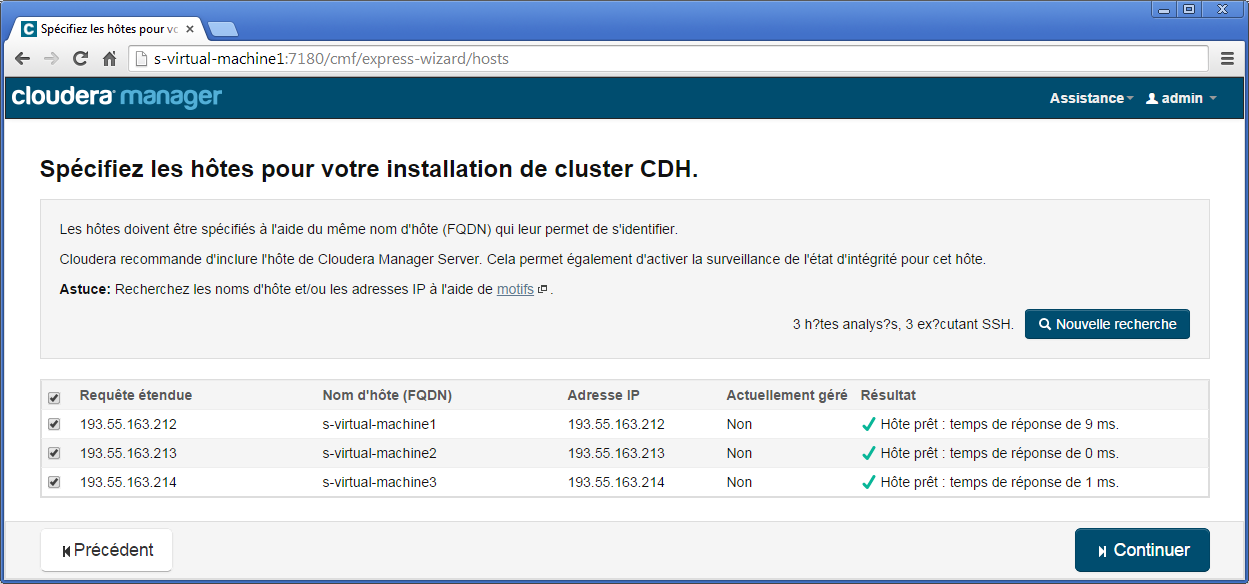
À la première étape d'installation du cluster, laissez les paramètres par défaut en vous assurant que la version Cloudera Hadoop 5 est sélectionnée (CDH-5.x.y-z.w), puis cliquez Continuer.
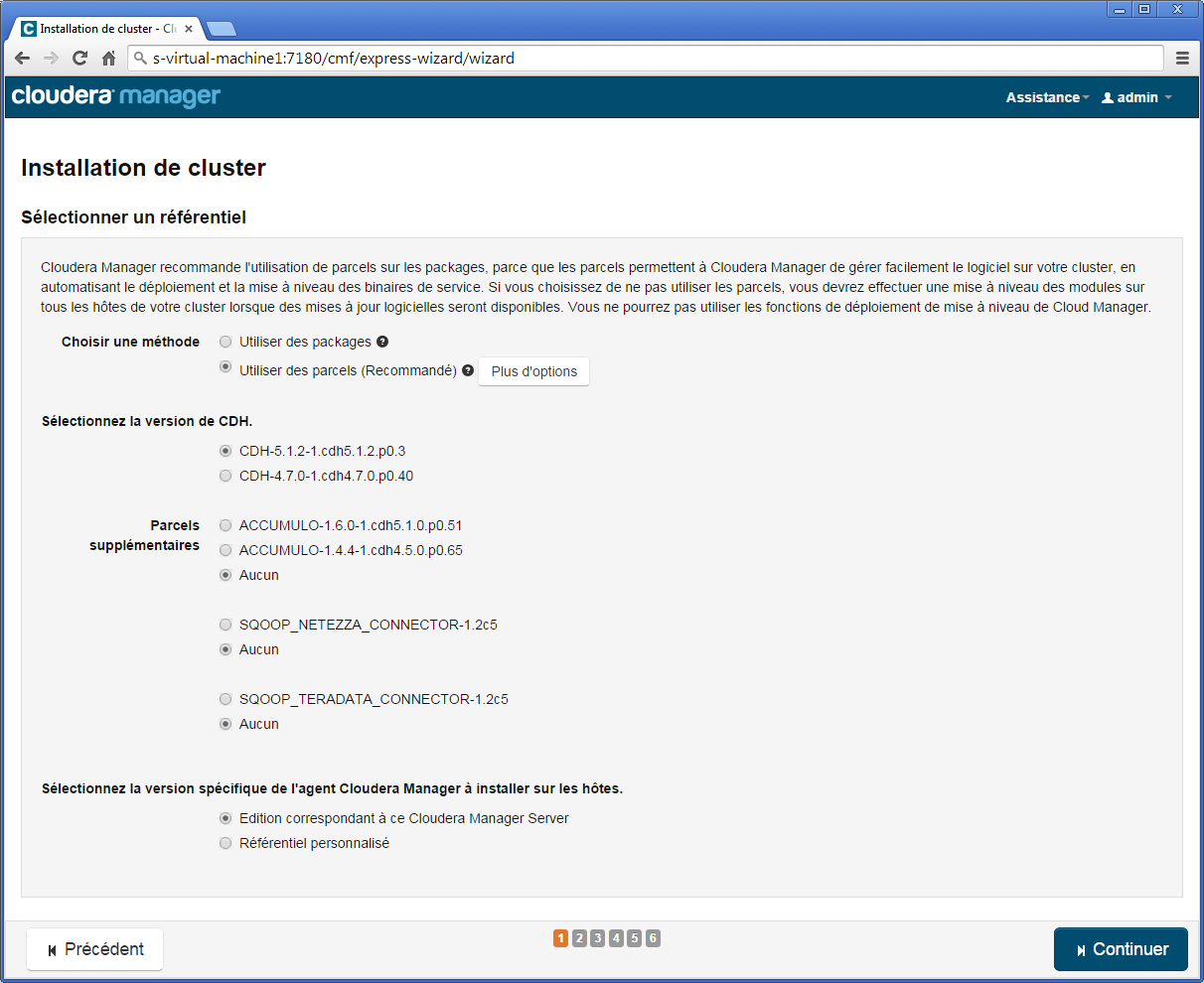
À la deuxième étape, ne cochez pas « Installer les fichiers de politique de cryptage de niveau illimité Java », puis cliquez Continuer.
À la troisième étape, sélectionnez l'option Un autre utilisateur et saisissez la valeur hadoopmanager, saisissez le mot de passe deux fois hadoopmanager, puis cliquez Continuer.
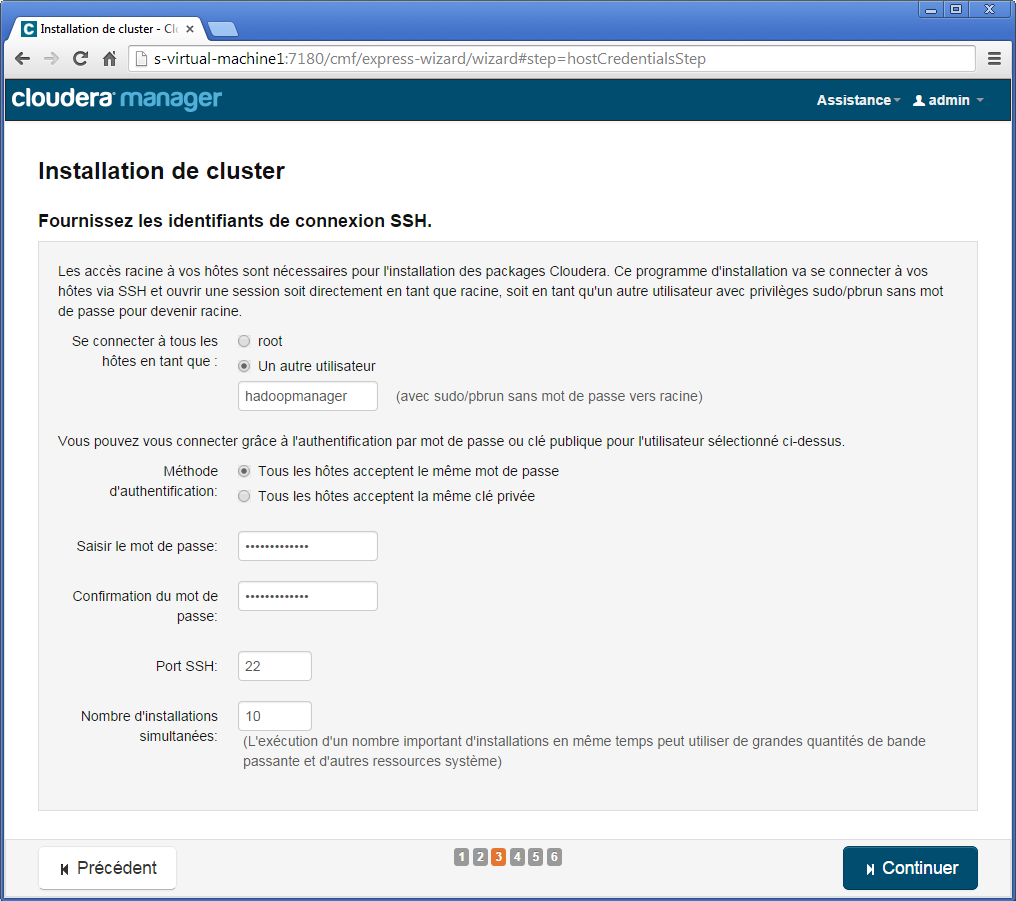
À la quatrième étape, l'installation du cluster démarre et après un petit temps vous devriez obtenir l'écran suivant.
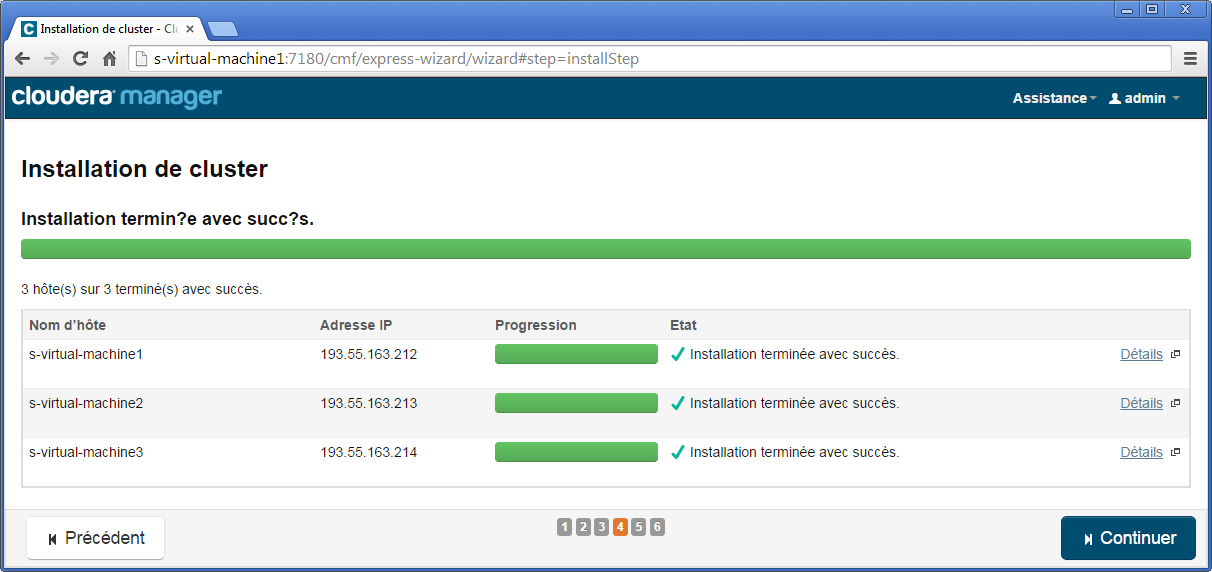
La cinquième étape consiste à installer les différentes parcels (équivalent à des paquets, mais adaptées au déploiement sur un cluster Hadoop Cloudera). Dans la suite, nous utiliserons indifféremment le mot module pour désigner parcel.
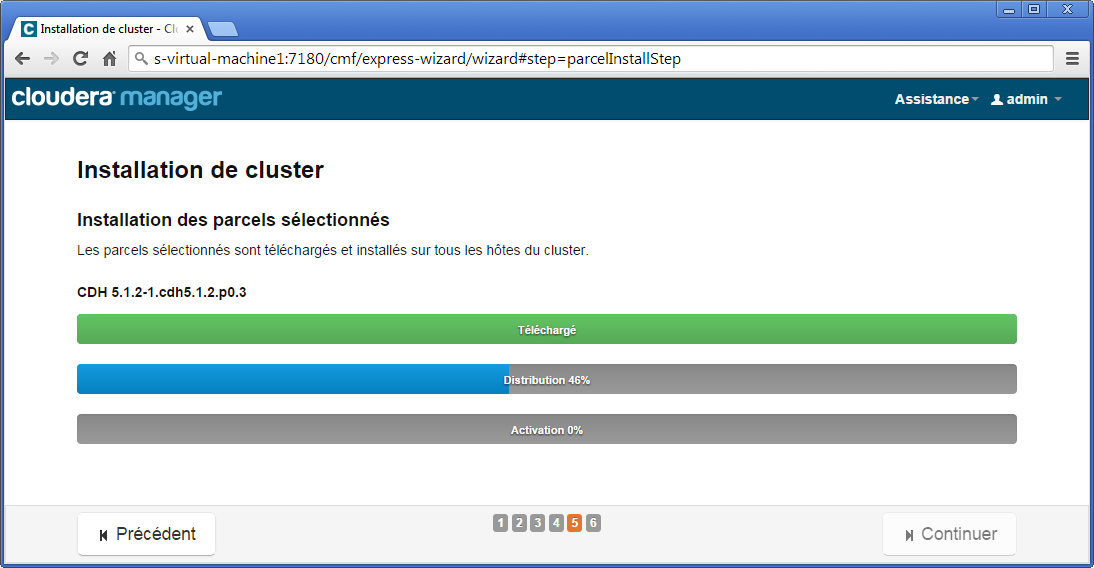
Finalement à la sixième étape, un récapitulatif est donné.
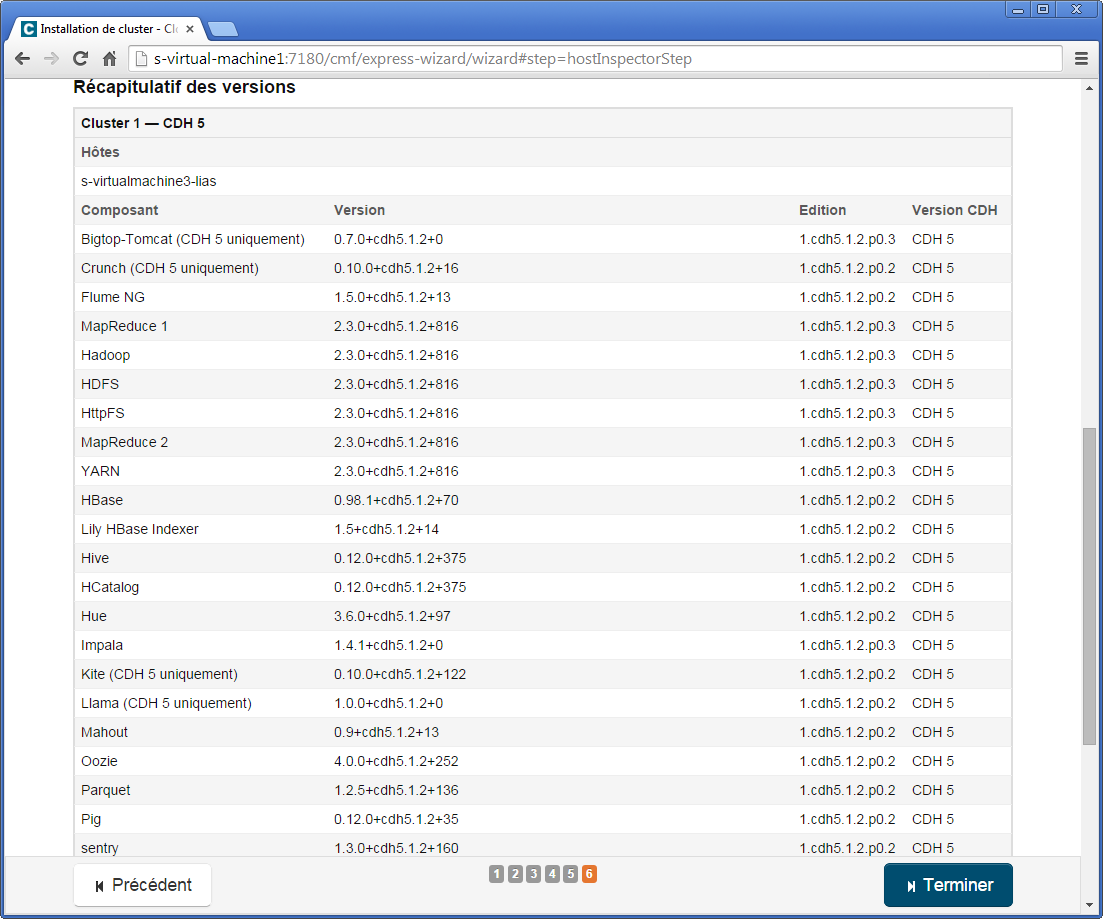
IV-C. Configuration d'un cluster trois nœuds▲
À la suite de l'installation, Cloudera Manager vous propose désormais de configurer le cluster.
À la première étape, il vous est demandé de sélectionner les services à installer sous forme de combinaison. Choisissez la première option Core Hadoop. Cette combinaison contient HDFS, Yarn (MapReduce 2), Zookeeper, Oozie, Hive, Hue et Sqop. Ces projets seront suffisants pour réaliser nos expérimentations.

À la deuxième étape, différentes options pour les affectations des rôles sont proposées. Assurez-vous de mettre la valeur de DataNode dans la catégorie HDFS à Tous les hôtes de façon à ce que le premier nœud soit à la fois NameNode et DataNode.
Par ailleurs, grâce à ces options, vous pourriez choisir par exemple la machine qui prendrait en charge le NameNode ou choisir de désactiver le secondary NameNode. Veuillez noter que la plupart des informations sont modifiables une fois les nœuds installés.
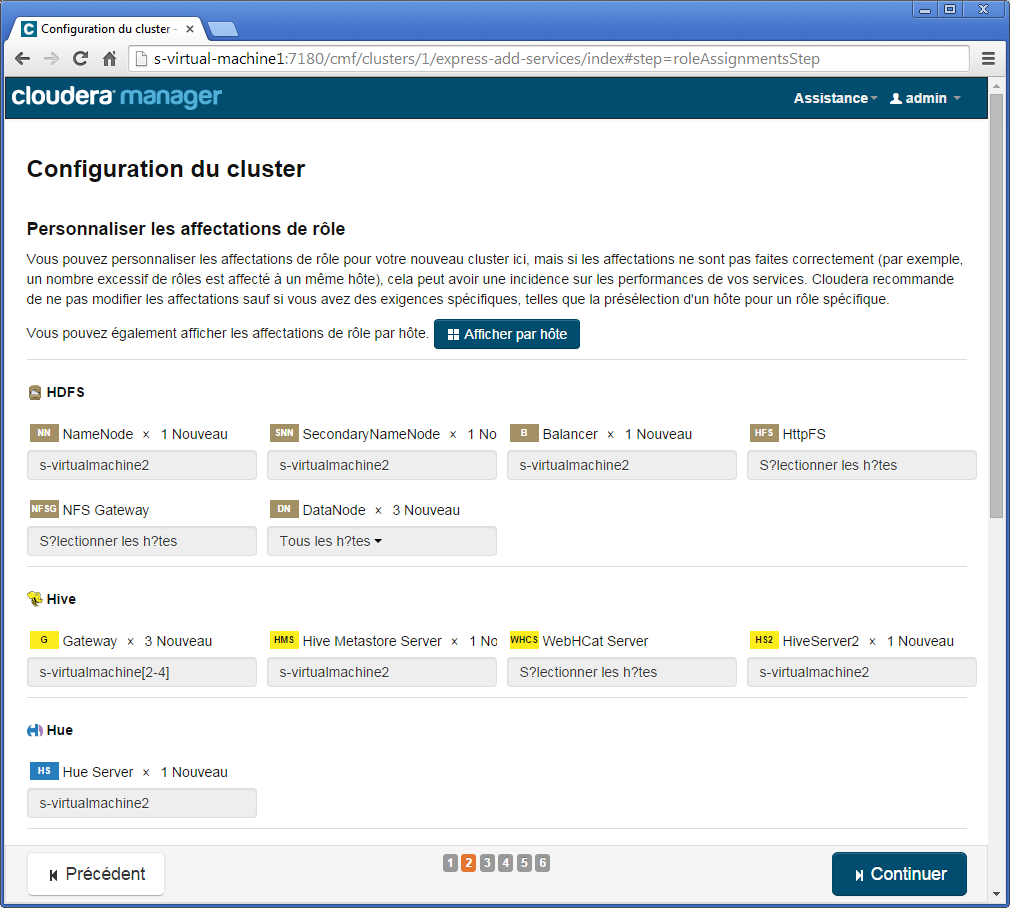
À la troisième étape, des options liées aux configurations des bases de données traditionnelles utiles par exemple pour Hive. Faites simplement Tester la connexion.
À la quatrième étape, vous avez la possibilité de modifier certaines configurations d'Hadoop et des sous-projets installés. Vous pourriez par exemple modifier le répertoire de données DataNode qui correspond au dossier HDFS. Nous laisserons les valeurs par défaut.
À la cinquième étape, la configuration démarre.
Finalement, l'écran de l'étape 6 vous félicite d'avoir réussi à installer un cluster Hadoop Cloudera à deux nœuds. Étudions maintenant l'interface d'administration de Cloudera Manager.
IV-D. Interface d'administration du cluster▲
L'interface d'administration du cluster est présentée sur la figure ci-dessous.
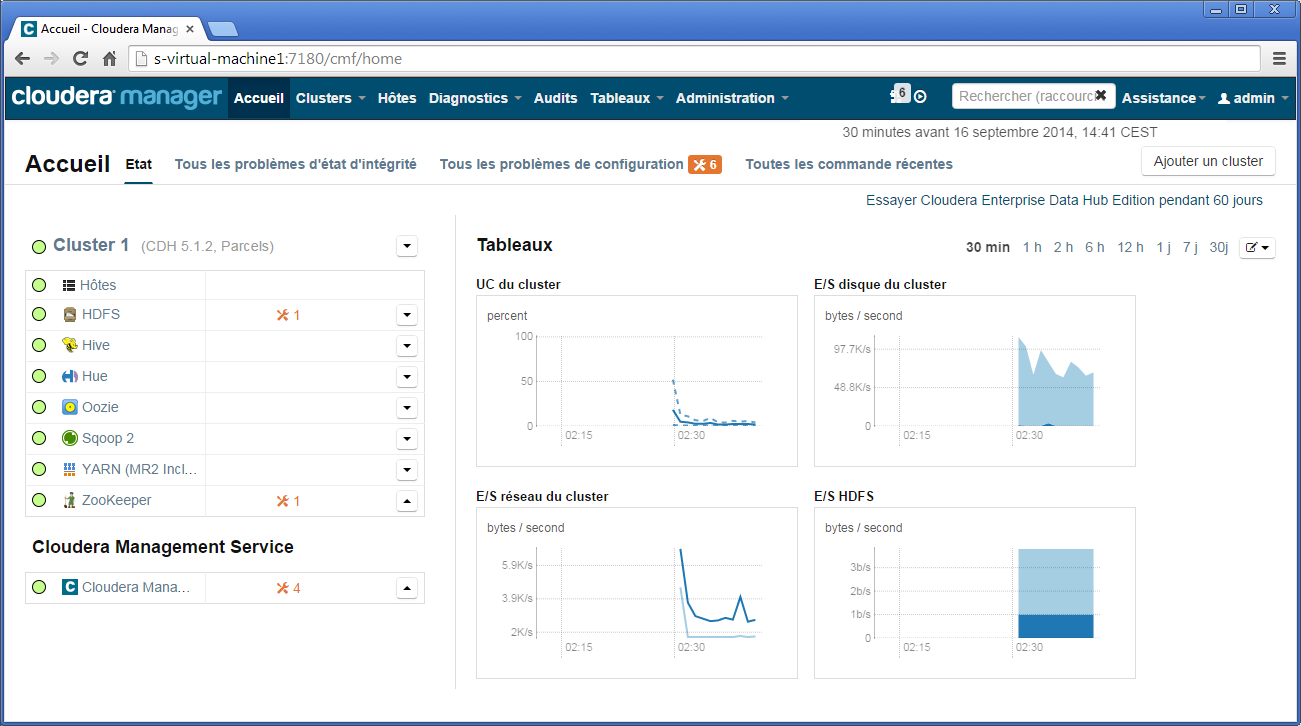
Sans trop vouloir détailler, cette interface permet d'obtenir une vision globale du cluster, que ce soit au niveau matériel (les nœuds du cluster) ou des modules installés (HDFS, Hive…).
- Sur la partie gauche sont donnés les différents modules installés avec leur état (pastilles vertes indiquant un fonctionnement correct).
- Sur la partie haute sous forme de bandeau horizontal, sont fournis des accès aux fonctionnalités principales (Clusters, Hôtes, Diagnostics, Audits, Tableaux et Administrations).
- Sur la partie centrale est présenté un tableau de bord à base de graphiques. Il permet de visualiser différentes métriques du cluster. On peut retrouver des métriques notamment pour mesurer les entrées/sorties sur HDFS, sur le temps d'exécution d'un job, sur l'occupation processeur, etc. (l'ensemble des métriques est décrit dans la documentation officiellede Cloudera Manager). Les métriques peuvent cibler le cluster dans sa globalité ou des nœuds en particulier. Cette granularité est pratique si vous souhaitez monitorer uniquement le NameNode pour connaître l'occupation mémoire. La figure ci-dessus par exemple présente les entrées/sorties des disques, du réseau, de HDFS et l'occupation processeur. Ces métriques peuvent être exportées sous différents formats exploitables comme JSON ou CSV via une API Rest (API Rest Cloudera V6). Un peu plus tard dans ce tutoriel, nous montrerons comment accéder à ces métriques via un script, afin de montrer le comportement du cluster lors de l'exécution d'un Job MapReduce. Enfin, ce tableau de bord est paramétrable et il est possible d'ajouter de nouveaux graphiques suivant de nombreux critères. Une interface simpliste basée sur le langage de requête tsquery « à la SQL » est fournie (voir figure suivante).
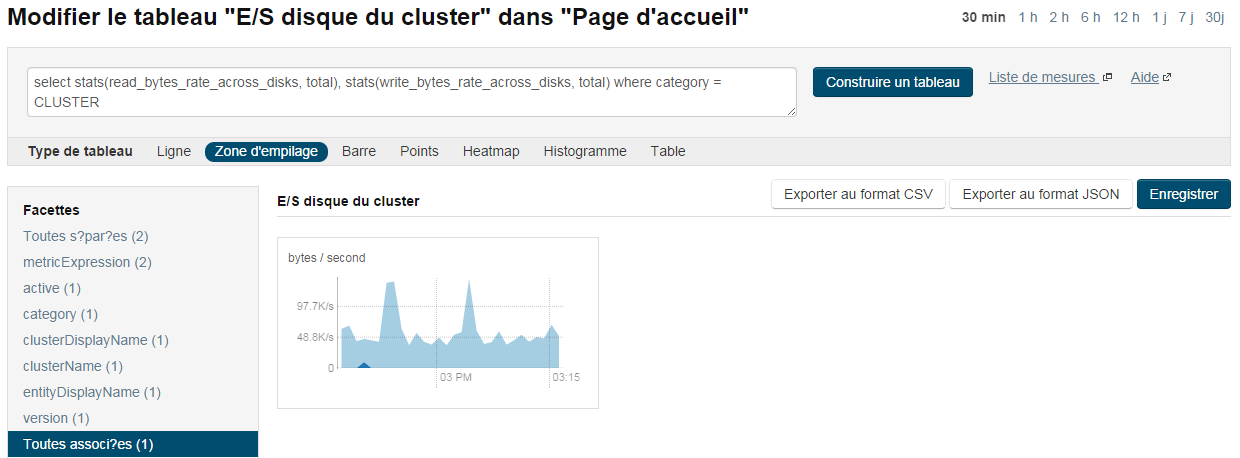
IV-E. Ajout d'un nœud DataNode au cluster▲
Dans cette section, nous nous intéressons à ajouter un nœud supplémentaire (appelé Hôtes sous Cloudera Manager) de données (DataNode) à notre cluster. Pour rappel, ce dernier est actuellement composé d'un nœud NameNode/DataNode et de deux nœuds DataNode. La capacité du système de fichiers HDFS avec trois nœuds de données est de ~ 1 To (2x500 Go). Cette information est visible depuis l'interface dédiée au module HDFS. Nous souhaitons donc passer à trois nœuds de données et nous assurer que l'ajout d'une nouvelle machine augmentera la taille de notre système de fichiers.
Lorsqu'un nouveau nœud est intégré à un cluster, un certain nombre de modules doivent être installés. Ces modules sont regroupés dans des modèles (template). Par exemple, suite à l'installation et à la configuration de notre cluster trois nœuds, les deux nœuds spécifiques DataNode s-virtual-machine2 et s-virtual-machine3 avaient un modèle différent du nœud NameNode. Ce modèle appelé Template - 1 dédié au DataNode contient les modules suivants : DataNode Default Group, Gateway Default Group et NodeManager Default Group. L'intérêt des modèles est de pouvoir réaliser des regroupements et de les appliquer à un nouveau nœud, ce que nous allons réaliser par la suite en ajoutant s-virtual-machine4 au cluster.
Sélectionnez depuis le bandeau le menu hôte puis faites Ajouter de nouveaux hôtes au cluster.
Ajoutez le nœud identifié par le nom s-virtual-machine4 puis cliquez Continuer.
Le reste de l'installation et de la configuration restent similaires à ce que nous avions déjà rencontré lors de la section Installation d'un cluster 1 NameNode 1 DataNodeInstallation et configuration d'un cluster multinœud.
À l'étape 7, il vous est demandé de choisir un modèle d'hôte. Choissez le modèle Template - 1. Si ce modèle n'existe pas, créez-le avec les modules suivants pour rappel : DataNode Default Group, Gateway Default Group et NodeManager Default Group.

À l'étape finale 8, vous devriez obtenir l'écran suivant.
Afin de valider les modifications sur le Cluster, vous devrez Déployer la configuration Client et faire Rédémarrer le cluster. Ces options sont disponibles depuis la vue cluster.
On aperçoit clairement l'intérêt de Cloudera Manager. Il s'occupe des changements à opérer sur les fichiers de configuration. Il vous suffira de redémarrer le serveur afin que ces changements soient appliqués.
Il est à noter qu'il est possible d'ajouter un nœud déjà préparé dans le sens où il avait précédemment intégré le cluster. À ce moment-là, l'ajout du nœud va consister à le réintégrer dans la configuration du serveur puis à démarrer ses différents services.
V. Préparation des expérimentations : jeu de données et outils▲
Notre expérimentation vise à montrer les objectifs suivants :
- l'augmentation du nombre de nœuds a une importance pour distribuer l'exécution d'un programme MapReduce et réduire son temps d'exécution ;
- la redondance des données assure un niveau de fiabilité pour le système Apache Hadoop, par exemple suite à une panne sur un de ses nœuds ;
- l'utilisation du patron de conception MapReduce associé au framework Apache Hadoop facilite le développement de programme distribué ;
- l'identification des facteurs limitants (sollicitations excessives du CPU et/ou des disques durs).
Pour l'expérimentation, nous utiliserons le programme de comptage de mots (WordCount) que nous avions utilisé dans le tutoriel précédent. Il ne subira pas de modification, il sera conforme à la version disponible dans la distribution de Hadoop. Le facteur de réplication (paramètre dfs.replication) sera laissé à 3, sa valeur par défaut.
Nous utiliserons également les données issues du site Web Gutenberg en nous basant sur l'œuvre intégrale de William Shakespeare (~5 Mo). Pour obtenir une taille relativement élevée de fichiers (via un fichier de 50 Go par exemple), nous avons élaboré un petit script Bash qui va générer un fichier de plus grande taille à partir de ce fichier de 5 Mo.
Pour montrer l'intérêt d'Hadoop, nous avons développé un programme Java ad hoc dont le but est de paralléliser le comptage de mots depuis une seule machine physique. La principale limite de notre programme Java sera l'absence d'exécution distribuée, le but n'étant pas de redévelopper le framework Apache Hadoop.
Dans la suite de cette section, nous allons détailler les différents codes développés pour générer notre jeu de données et notre programme ad hoc en Java, puis nous importerons le jeu de données sous HDFS et configurerons le job MapReduce WordCount via l'interface Hue. Enfin, nous présenterons les outils qui serviront à capturer les métriques (occupation CPU, taux d'utilisation disque…) pour en déterminer les facteurs limitants.
Il est à noter qu'il existe de nombreux benchmarks pour tester les performances d'un système Hadoop. Sans être exhaustif, voici les plus représentatifs :
- HiBench : https://github.com/intel-hadoop/HiBench ;
- GridMix : http://hadoop.apache.org/docs/r1.2.1/gridmix.html ;
- DFSIO : disponible de base dans la distribution Hadoop ;
- YCSB : https://github.com/brianfrankcooper/YCSB/.
V-A. Initialisation du jeu de données▲
Nous présentons ci-dessous un script Bash dont la fonction est de prendre en paramètre une source texte (paramètreB1) et d'ajouter son contenu n fois (paramètre 3) dans un fichier de sortie (paramètre 2). Les paramètres 2 et 3 sont optionnels et des valeurs par défaut sont définies, bigfile.txt pour le fichier de sortie et 10 000 pour le nombre d'itérations.
2.
3.
4.
5.
6.
7.
8.
#!/bin/bash
OUTPUT=${2:-bigfile.txt}
ITERATE=${3:-10000}
for ((c=1; c<=$ITERATE; c++))
do
cat $1 >> $OUTPUT
done
Téléchargez donc le fichier lié à l'œuvre intégrale de William Shakespeare, puis exécuter la commande suivante
$ ./createbigfile.sh 100.txt 50big100.txt 10000Ceci va construire un fichier 50big100.txt d'une capacité de ~54 Go.
Le code complet du script createbigfile.sh est disponible sur mon Github.
V-B. Programme ad hoc en Java de comptage de mots▲
Les paramètres de ce programme ad hoc en Java sont les suivants :
- un fichier texte source contenant les mots à compter ;
- un nom de fichier de sortie qui contiendra pour chaque mot le nombre d'occurrences présentes ;
- un nom de fichier pour le rapport d'exécution qui contiendra des métriques sur le temps d'exécution ;
- le nombre d'instances de Thread dédié au comptage de mots.
Les modules du programme sont les suivants :
- un module type « contrôleur » qui traite les paramètres et coordonne tous les autres modules ;
- un module qui découpe le fichier en plusieurs parties afin d'alimenter les différentes instances du Thread dédié au comptage de mots ;
- un module de map, qui crée les instances de Thread et qui distribue les différentes parties du fichier ;
- un module de reduce, qui fusionne les résultats obtenus pour chaque instance de Thread ;
- un module de sortie de la partie reduce ;
- un module de sortie pour les rapports d'exécution.
Intéressons-nous à détailler le code de chaque module.
Le premier, code ci-dessous, concerne celui qui traite les paramètres et appelle successivement les cinq principaux modules (entre lignes 31 et 40).
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
public class WordCounterMultiThread {
public static void main(String[] args) throws NumberFormatException, IOException {
if (args == null) {
WordCounterMultiThread.displayArgumentsAreMissing();
return;
}
if (args.length == 4) {
new WordCounterMultiThread(args[0], args[1], args[2], Integer.parseInt(args[3]));
} else {
WordCounterMultiThread.displayArgumentsAreMissing();
return;
}
}
private static void displayArgumentsAreMissing() {
System.out.println("Arguments are missing.");
System.out.println(" - The first argument must specify the source file.");
System.out.println(" - The second must specify the output file.");
System.out.println(" - The third must specify the report file.");
System.out.println(" - The fourth the thread number.");
}
public WordCounterMultiThread(String source, String destination, int pChunksNumber) throws IOException {
start = System.currentTimeMillis();
maxThreads = Runtime.getRuntime().availableProcessors();
fileProcessors = new ArrayList<FileProcessor>();
sourceFile = new File(source);
this.chunksNumber = pChunksNumber;
// 1-Determine the offsets.
offsets = this.split();
// 2-Execute threads.
this.map();
// 3-Reduce the Map.
this.reduce();
// 4-Write the output.
this.printAllCounts(destination);
// 5-Print the report.
this.printReport(report);
}
...
La fonction long[] split découpe le fichier en plusieurs parties. Un RandomAccessFile (ligne 45) est utilisé afin de changer et récupérer la position du curseur de lecture. La position de chaque début de partie est stockée dans un tableau d'entiers (long[] offsets).
44.
45.
46.
47.
48.
49.
50.
51.
52.
53.
54.
55.
56.
57.
58.
59.
60.
61.
62.
63.
64.
65.
private long[] split() throws IOException {
long[] offsets = new long[chunksNumber];
RandomAccessFile raf = new RandomAccessFile(sourceFile, "r");
if (chunksNumber == 1) {
offsets[0] = 0;
} else {
for (int i = 1; i < chunksNumber; i++) {
raf.seek(i * sourceFile.length() / chunksNumber);
while (true) {
int read = raf.read();
if (read == '\n' || read == -1) {
break;
}
}
offsets[i] = raf.getFilePointer();
}
}
raf.close();
finishSplit = System.currentTimeMillis();
return offsets;
}
Nous présentons ci-dessous la méthode map().
Deux types de Thread sont gérés. Le premier type de Thread concerne FileProcessor est s'occupe de compter pour une partie du fichier les mots. Le résultat est stocké dans une TreeMap. Le second type de Thread concerne ConsoleProcessor qui gère l'affichage. Seule une instance de ce Thread sera créée (ligne 70).
Pour la gestion des instances multiples des Threads, nous faisons appel à ExecutorService. Le nombre d'instances de Thread est borné au nombre de Threads demandé en paramètre plus un Thread supplémentaire dédié à l'affichage sur console (ligne 69).
L'instruction de la ligne 81, permet de mettre en attente le Thread courant tant que les instances des Threads FileProcessor et ConsoleProcessor n'ont pas terminé leur exécution.
68.
69.
70.
71.
72.
73.
74.
75.
76.
77.
78.
79.
80.
81.
82.
83.
84.
85.
86.
87.
88.
89.
90.
91.
92.
93.
94.
95.
96.
97.
98.
99.
100.
101.
102.
103.
104.
105.
106.
107.
108.
109.
110.
111.
112.
113.
114.
115.
116.
117.
public void map() {
// Process each chunk using a thread for each one
ExecutorService service = Executors.newFixedThreadPool(chunksNumber + 1);
service.execute(new ConsoleProcessor(fileProcessors));
for (int i = 0; i < chunksNumber; i++) {
long startOffsets = offsets[i];
long end = i < chunksNumber - 1 ? offsets[i + 1] : sourceFile.length();
final FileProcessor newFileProcessor = new FileProcessor(i,sourceFile, startOffsets, end);
fileProcessors.add(newFileProcessor);
service.execute(newFileProcessor);
}
service.shutdown();
try {
service.awaitTermination(Long.MAX_VALUE, TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
}
finishMap = System.currentTimeMillis();
}
class FileProcessor implements Runnable {
private TreeMap<String, Integer> frequencyData = new TreeMap<String, Integer>();
public void run() {
try {
RandomAccessFile raf = new BufferedRandomAccessFile(file, "r");
raf.seek(start);
String word; Integer count;
while (raf.getFilePointer() < end) {
String line = raf.readLine();
if (line == null) {
continue;
}
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word = tokenizer.nextToken();
count = getCount(word, frequencyData) + 1;
frequencyData.put(word, count);
}
percentage = Math.round(((raf.getFilePointer() - start) * 100) / (end - start));
}
raf.close();
} catch (IOException e) {
// Deal with exception.
}
}
}
Dans le code ci-dessous, nous présentons la méthode reduce(). Son travail consiste à fusionner l'ensemble des TreeMap de chaque instance de Thread de FileProcessor.
120.
121.
122.
123.
124.
125.
126.
127.
128.
129.
130.
131.
132.
public void reduce() {
for (FileProcessor current : fileProcessors) {
for (String key : current.getFrequencyData().keySet()) {
if (frequencyData.containsKey(key)) {
frequencyData.put(key, frequencyData.get(key) + current.getFrequencyData().get(key));
} else {
frequencyData.put(key, current.getFrequencyData().get(key));
}
}
}
finishReduce = System.currentTimeMillis();
}
...
}
Le code complet de ce programme est disponible sur mon Github.
L'exécution de ce programme sera faite dans la section suivante dédiée à l'expérimentationExpérimentation.
V-C. Importation du jeu de données dans HDFS▲
Le fichier 50big100.txt d'une capacité respective de ~50 Go doit être copié dans le système de fichiers HDFS afin de pouvoir exécuter le job MapReduce correspondant. Nous utiliserons la commande hadoop fs déjà étudiée dans le deuxième tutoriel.
Exécutez les instructions ci-dessous et patientez quelques instants, le temps que la copie soit terminée.
$ sudo -u hdfs hadoop fs -put 50big100.txt /user/hdfs/books/50big100.txtComme la taille d'un bloc HDFS est configurée à 128 Mo, 417 blocs seront nécessaires pour stocker ce fichier sur le système de fichiers. Ainsi, lors de l'exécution du job MapReduce, 417 tâches map devront être créées.
V-D. Configuration du job MapReduce▲
V-D-1. Configuration du job MapReduce : solution par Hue▲
Avant de configurer le job MapReduce depuis Hue, le programme Java MapReduce du WordCount (hadoop-mapreduce-examples.jar) doit être placé dans HDFS. Sous Cloudera et si vous avez choisi la gestion des packages par facets, le fichier jar se trouve dans ce répertoire /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce
Supposons que vous soyez dans le répertoire où se trouve le fichier hadoop-mapreduce-examples.jar, la commande pour ajouter l'archive jar est la suivante :
$ sudo -u hdfs hadoop fs -put hadoop-mapreduce-examples.jar /user/hdfsDepuis l'application Web Hue (http://s-virtual-machine1:8888), sélectionnez le menu Éditeurs de requêtes, puis cliquez sur Job Designer.
Choisissez Nouvelle Action et sélectionnez Java
Saisissez ensuite, les valeurs comme cela est indiquée ci-dessous :
- Nom : WordCount ;
- Chemin des fichiers Jar : /user/hdfs/hadoop-mapreduce-examples.jar ;
- Main Class : org.apache.hadoop.examples.WordCount ;
- Args : /user/hdfs/books /user/hdfs/output.
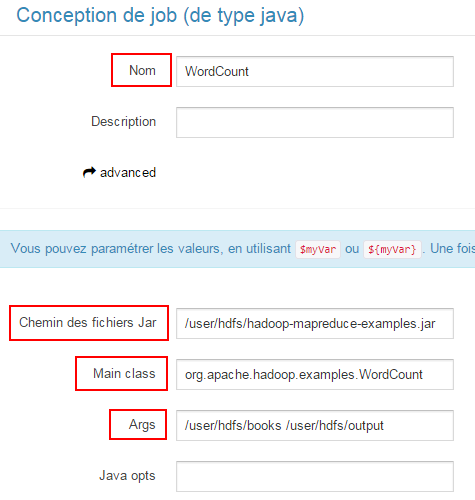
Finalement, validez en enregistrant vos informations.
V-D-2. Configuration du job MapReduce : solution par le Shell▲
Une autre option est d'exécuter le job MapReduce depuis l'invite de commande de Linux comme nous l'avions fait dans le tutoriel précédent.
La commande à exécuter sera la suivante :
$ sudo -u hdfs hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar wordcount /user/hdfs/books /user/hdfs/outputIl faudra faire attention dans ce cas à ce que votre terminal ne soit pas arrêté tout au long de l'exécution de votre job. Vous pourriez penser par exemple à utiliser l'outil Screen qui est un multiplexeur de terminaux.
V-E. Supervision : outils et métriques ciblées▲
Nous détaillons dans cette section les outils qui nous serviront à générer les métriques pour notre expérimentation. Deux outils seront utilisés : iostat pour l'exécution de notre programme ad hoc Java et le tableau de bord de Cloudera Manager pour l'exécution du job MapReduce. Nous focaliserons notre analyse sur le temps d'exécution et sur les données liées à l'occupation du processeur et du disque dur.
V-E-1. Programme ad hoc en Java▲
L'outil iostat donne des mesures sur les entrées/sorties des disques et donne également des informations sommaires sur l'occupation du processeur.
L'installation se fera sur une seule machine physique via le package sysstat qui contient l'outil iostat.
$ sudo apt-get install sysstatUn exemple d'utilisation de l'outil iostat est donné ci-dessous.
$ iostat -xt 2
Linux 3.11.0-15-generic (s-virtual-machine1) 11/10/14 _x86_64_ (2 CPU)
11/10/14 17:44:13
avg-cpu: %user %nice %system %iowait %steal %idle
12.49 0.00 0.92 0.11 0.13 86.36
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
xvda 0.00 3.26 1.42 5.87 57.95 102.62 44.05 0.12 16.22 8.55 18.06 0.55 0.40
11/10/14 17:44:15
avg-cpu: %user %nice %system %iowait %steal %idle
16.19 0.00 0.78 0.00 0.26 82.77
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
xvda 0.00 7.00 0.00 3.00 0.00 42.00 28.00 0.00 1.33 0.00 1.33 1.33 0.40Les paramètres x et t désignent respectivement un affichage étendu pour les métriques et un affichage de la date et heure. Le chiffre 2 en dernier paramètre précise la fréquence de rafraichissement.
Les colonnes qui vont nous intéresser sont %user, %system et %util qui correspondent respectivement à l'occupation CPU des programmes de l'utilisateur en cours, au taux d'utilisation du CPU pour le système et finalement aux taux d'utilisation du disque.
Afin de pouvoir traiter les données générées par iostat, l'outil awk a été utilisé pour générer un fichier CSV en sortie. Le code ci-dessous montre comment cela a été réalisé.
2.
3.
4.
5.
6.
7.
8.
9.
#!/bin/bash
...
iostat $frequency -xt | awk -v r=$outputiostat '
NF==2 {
getline;getline;uservar=$1;systemvar=$3;getline;getline;getline;
print uservar+systemvar";"$14 > r
}
' &
...
Ci-dessous est donné un exemple d'un fichier CSV généré où sont présentés deux colonnes séparées par ; dont la première constitue la somme des informations %user et %system et la seconde constitue les informations de %util.
6.85;0.69
0;0.40
0;0.00
0.12;0.00
13.63;4.10
50.56;2.20
50.19;2.70
50;3.30
...Pour la génération des graphiques à partir des données CSV, nous avons utilisé gnuplot. Nous montrons ci-dessous le code gnuplot qui nous servira pour générer les graphiques. Nous avons utilisé des variables (sizeinput, splitvalue, mapvalue, reducevalue, reportpng, outputiostat et frequency) pour paramétrer ce script.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
set terminal pngcairo color dashed enhanced size 800,500
set title sizeinput
set label 1 "Finish Split=".splitvalue."s" at splitvalue+100,20
set arrow from splitvalue,0 to splitvalue,80 nohead
set label 2 "Finish Map=".mapvalue."s" at mapvalue-10,40 right
set arrow from mapvalue,0 to mapvalue,80 nohead
set label 3 "Finish Reduce=".reducevalue."s" at reducevalue-10,60 right
set arrow from reducevalue,0 to reducevalue,80 nohead
set datafile separator ';'
set xlabel "Time (hh:mm:ss)"
set ylabel "Percentage (%)"
set xdata time
set xtics 1000
set xtics format "%H:%M:%S"
set output reportpng
set yrange [0:100]
plot outputiostat using ($0*frequency):1 w l lt rgb "#0000FF" title 'CPU usage', outputiostat using ($0*frequency):2 w l lt rgb "#FF0000" title 'Disk usage'
Le code complet des scripts startwcjbench.sh et wcbench.plt sont disponibles sur mon Github.
V-E-2. Job MapReduce▲
Les métriques fournies graphiquement dans le tableau de bord de Cloudera Manager sont disponibles également via une API Rest. Sa documentation est accessible depuis l'hôte qui héberge Cloudera Manager. Dans notre cas, il s'agit de http://s-virtual-machine1:7180/static/apidocs/index.html.
On va donc utiliser cette API Rest pour accéder à la ressource timeseries afin de récupérer, dans des fichiers CSV pour une plage de temps voulue, les données suivantes :
- l'occupation moyenne du CPU au niveau du cluster ;
- l'utilisation moyenne du disque au niveau du cluster ;
- l'occupation du CPU (temps utilisateur + système) au niveau de chaque nœud ;
- l'utilisation du disque au niveau de chaque nœud.
Les requêtes tsquery nécessaires pour cela seront les suivantes :
- select stats(utilization_across_disks, avg) where category = CLUSTER
- select stats(cpu_percent_across_hosts,avg) where category = CLUSTER
- select utilization where category = disk and hostname=$nodename and logicalPartition = false
- select cpu_user_rate / getHostFact(numCores, 1) * 100 + cpu_system_rate /getHostFact(numCores, 1) * 100 where hostname=$nodename
Un script Bash a été écrit afin de pouvoir récupérer depuis des requêtes HTTP/GET les fichiers CSV et générer des graphiques avec Gnuplot. Afin d'examiner comment faire appel à l'API REST, vous trouverez un échantillon du script ci-dessous.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
#!/bin/bash
...
wget -q --user=$USER --password=$PASSWORD -O $outputData/clusterioutilization.csv "$SERVER/api/v7/timeseries?query=select stats(utilization_across_disks, avg) where category = CLUSTER&contentType=text/csv&from=$STARTDATE&to=$FINISHDATE&desiredRollup=RAW"
wget -q --user=$USER --password=$PASSWORD -O $outputData/clustercpuusage.csv "$SERVER/api/v7/timeseries?query=select stats(cpu_percent_across_hosts,avg) where category = CLUSTER&contentType=text/csv&from=$STARTDATE&to=$FINISHDATE&desiredRollup=RAW"
...
gnuplot << EOF
set title "CPU & Disk usage during a WordCount MapReduce execution ($# nodes, 50 Gb bigfile.txt)"
set terminal pngcairo size 800,500
set output "$outputImage/mrclustercpuio$#.png"
set datafile separator ','
set xlabel "Time (hh:mm)"
set ylabel "Percentage (%)"
set xtics format "%H:%M"
set xdata time
set yrange [0:100]
set grid x y
plot "$outputData/clusterioutilization.csv" using (\$0*60):4 w l lt rgb "#FF0000" title 'Disk utilization', "$outputData/clustercpuusage.csv" using (\$0*60):4 w l lt rgb "#0000FF" title 'CPU Usage'
EOF
...
Dans les détails, les paramètres de requête pour l'API Rest sont les suivants :
- query : une requête de type tsquery ;
- contentType : le type de sortie (CSV ou JSON) ;
- from : la date départ ;
- to : la date de fin ;
- desiredRollup : le densité du contenu ;
Une fois la requête HTTP/GET appelée, un fichier CSV est récupéré qui est utilisé par Gnuplot pour générer les graphiques associés.
La totalité du script generatehadoopplot.sh est disponible sur mon Github.
L'interface Web dédiée à l'historisation des exécutions des jobs MapReduce http://s-virtual-machine1:19888/jobhistory peut également donner des métriques intéressantes. Nous nous en servirons pour connaître le début et la fin des exécutions et les temps moyens des tâches map et reduce.
VI. Expérimentation▲
Cette section s'intéresse aux expérimentations du programme Java ad hoc et du programme MapReduce dédiés à déterminer le nombre d'occurrences de mots depuis un fichier texte.
VI-A. Protocole d'expérimentation et exécution▲
Nous montrons pour chacun de nos deux programmes comment réaliser leurs exécutions et les fichiers obtenus.
VI-A-1. Programme ad hoc Java▲
Le programme ad hoc Java sera exécuté sur une machine virtuelle dont le nombre d'instances de Thread sera aligné avec le nombre de cœurs CPU. Il y aura donc six exécutions différentes et notre expérimentation débutera par un cœur, une instance de Thread puis deux cœurs, deux instances de Thread et ainsi de suite. La configuration du nombre de cœurs se fera manuellement depuis Xen Server.
Dans la section Préparation des expérimentations, jeu de données et outilsPréparation des expérimentations : jeu de données et outils, nous avons présenté un ensemble de scripts pour l'expérimentation via notre programme Java ad hoc (programme Java, script Gnuplot et commande iostat). Afin d'orchestrer l'exécution de ces différents scripts, nous utiliserons startwcjbench.sh étudié déjà en partie.
Les paramètres du script startwcjbench.sh sont les suivants :
- fréquence de captures pour iostat (par défaut fixée à 5) ;
- la source de données à analyser ;
- le nombre d'instances de Thread pour le programme Java à traiter.
Le script startwcjbench.sh s'occupera :
- de lancer iostat en arrière-plan afin de pouvoir mesurer le taux d'occupation CPU et disque et de générer un fichier CSV en sortie ;
- de lancer l'exécution du programme Java ad hoc avec un nombre d'instances de Thread donné.
Dans le cas de l'expérimentation que nous avons menée, nous avons utilisé un rafraichissement de quatre, le fichier 50big100.txt et jusqu'à six instances de Thread. Par exemple dans le cas d'une configuration avec cinq cœurs, la commande à exécuter sera la suivante :
$ ./startwcjbench.sh 4 50big100.txt 5Pour les six exécutions différentes (d'une durée totale d'environ huit heures) trois répertoires ont été créés où vous pourrez y retrouver :
- output_iostat : autant de fichiers iostati.csv que d'exécutions (où i est le numéro d'exécution) contenant pour chacun la sortie de iostat ;
- output_java : autant de fichiers outputi.txt que d'exécutions contenant pour chacun le résultat d'exécution du programme Java ad hoc de comptage de mots ;
- report_java : autant de fichiers reporti.txt et reporti.png que d'exécutions représentant respectivement le temps d'exécution et l'image générée à partir des CSV.
VI-A-2. Programme Hadoop▲
Les exécutions répétées (six au total) du job MapReduce WordCount sur un cluster ayant un nombre de DataNode différent requièrent quelques paramétrages.
- Le premier concerne la composition du cluster, il faut configurer le cluster pour ajouter un nouveau nœud DataNode (voir Ajout d'un nœud DataNode au cluster) ;
- Le deuxième concerne le fichier 50big100.txt à analyser. Afin d'assurer une répartition uniforme des blocs du fichier à travers tous les DataNode du cluster, pensez avant l'ajout d'un nouveau nœud à supprimer le fichier existant et à transférer une nouvelle fois.
- Le troisième concerne la suppression du répertoire output dans le HDFS. Celui-ci contient les résultats de l'exécution, il est créé à chaque exécution. Une erreur surviendra si le répertoire existe.
- Le quatrième concerne la génération des graphiques. Comme détaillé dans la section Tableau de bord de Cloudera ManagerJob MapReduce, avant toute réexécution, il est nécessaire de générer les graphiques de la précédente exécution. Nous discutons de ce point ci-après.
Pour l'exécution à proprement parler, depuis l'application Hue, affichez le contenu du Job Designer, choisissez votre configuration WordCount et faites Envoyer. Si tout se passe bien, votre job démarre et l'état d'exécution est disponible depuis le Job Browser (barre du menu à droite).
À la fin de l'exécution du job MapReduce WordCount, récupérez depuis l'interface Web Jobhistory (http://s-virtual-machine1:19888/jobhistory), la date de démarrage et la date de fin, puis exécutez le script generatehadoopplot.sh.
Les paramètres du script generatehadoopplot.sh sont les suivants :
- date de début d'exécution du job ;
- date de fin d'exécution du job ;
- la liste des hôtes à monitorer.
Par exemple, dans le cas d'une configuration d'un cluster avec deux DataNode, la commande à exécuter sera la suivante :
$ ./generatehadoopplot.sh 2015-01-21T18:43:00.000Z 2015-01-22T00:30:00.000Z s-virtualmachine1-lias s-virtualmachine2-liasPour les six exécutions différentes (d'une durée totale d'environ 12 heures) deux répertoires ont été créés où vous pourrez y retrouver :
- output_data : les fichiers CSV obtenus par l'appel à l'API Rest de Cloudera ;
- output_image : les images générées via Gnuplot à partir des fichiers CSV.
VI-B. Analyse des résultats : discussions▲
Nous donnons ci-après une analyse des résultats des exécutions du programme ad hoc et du MapReduce.
VI-B-1. Programme ad hoc Java▲
Le tableau ci-dessous présente le temps de traitement de chaque exécution avec un nombre d'instances de Thread/cœur différent. La dernière ligne du tableau présente l'évolution d'une exécution par rapport à sa précédente commençant par un Thread.
|
Nbre Thread/Cœur |
1 |
2 |
3 |
4 |
5 |
6 |
|---|---|---|---|---|---|---|
|
Temps exécution (hh:mm:ss) |
2h:29m:22s |
1h:11m:09s |
0h:48m:26s |
0h:37m:56s |
0h:29m:29s |
0h:27m:11s |
|
Évolution / à deux instances |
+0% |
-52% |
-31% |
-21% |
-22% |
-7% |
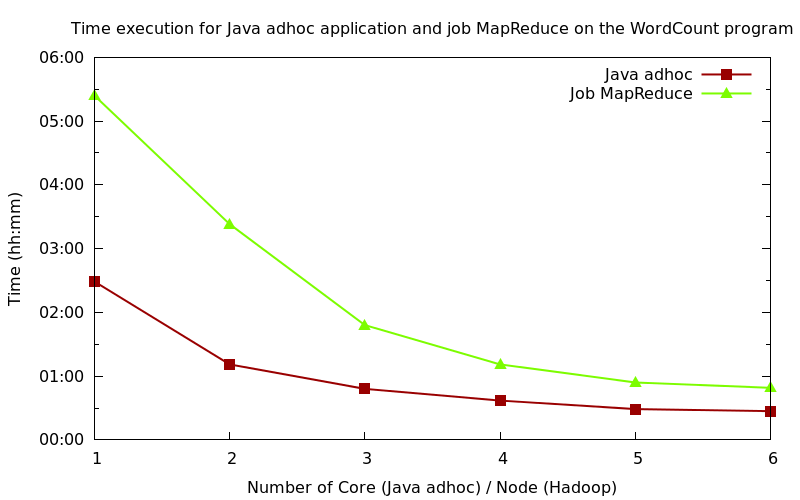
Nous pouvons remarquer rapidement sur le tableau que l'augmentation du nombre d'instances de Thread et de cœur améliore considérablement le temps d'exécution. Le pourcentage de diminution est plus flagrant sur le début que vers la fin.
Les six graphiques ci-dessous montrent les sollicitations du CPU et du disque dur avec un nombre d'instances de Thread et de cœur croissant (de une à six instances de Thread/cœur). La courbe en bleu désigne l'occupation CPU (utilisateur + système) tandis que la courbe en rouge désigne la sollicitation du disque dur. Pour chaque graphique, nous avons identifié les principales étapes d'exécution : le découpage, la phase de map et la phase de reduce. La phase de map est toujours la plus longue.
Un Thread▲
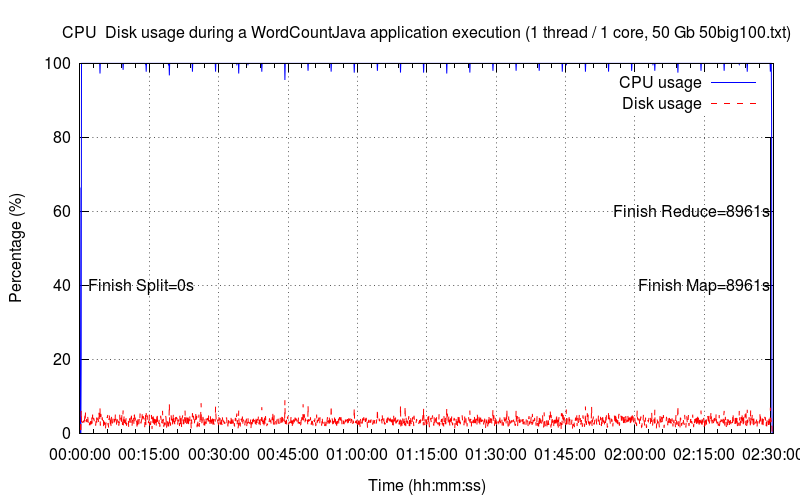
Dans le cas de cette première exécution, nous distinguons que l'occupation CPU est à son maximum, ce qui est cohérent puisque le nombre de cœurs est à 1. Cette remarque sera valable pour tous les graphiques suivants. Nous voyons sur le graphique que le facteur limitant de cette exécution est le CPU puisqu'il est à son maximum et que l'unité de disque est très peu sollicitée (~ 3 %).
Le temps de split tout comme le temps reduce sont infiniment petits par rapport à la tâche de map, ce qui explique les valeurs à 0 s.
Deux Threads▲
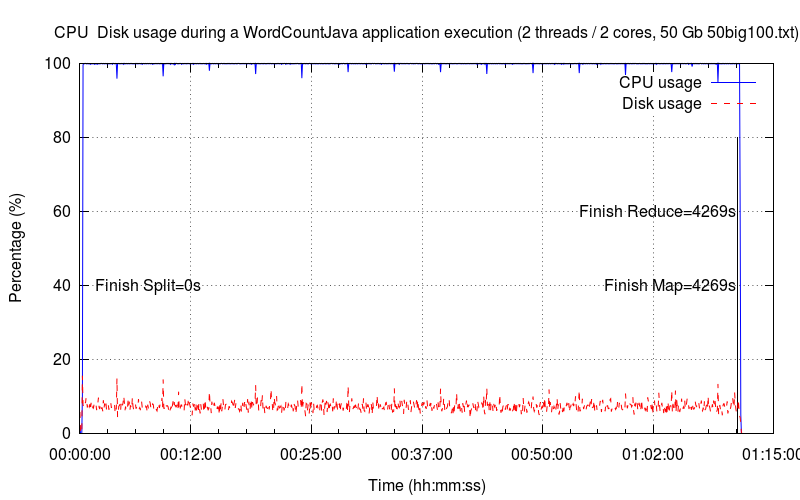
Dans ce deuxième graphique, peu de changement hormis le temps d'exécution qui a été divisé par deux. Le disque dur est relativement plus sollicité (~ 9 %) que sur le premier graphique, mais l'occupation CPU est toujours le facteur limitant.
Trois Threads▲
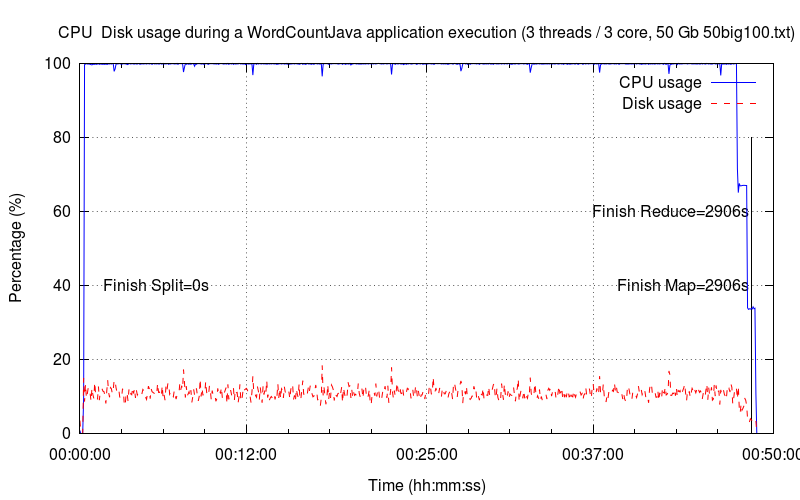
Peu de changement par rapport au graphique précédent, le temps d'exécution est descendu à moins d'une heure. Le taux d'utilisation du disque augmente légèrement (~ 12 %).
Quatre Threads▲
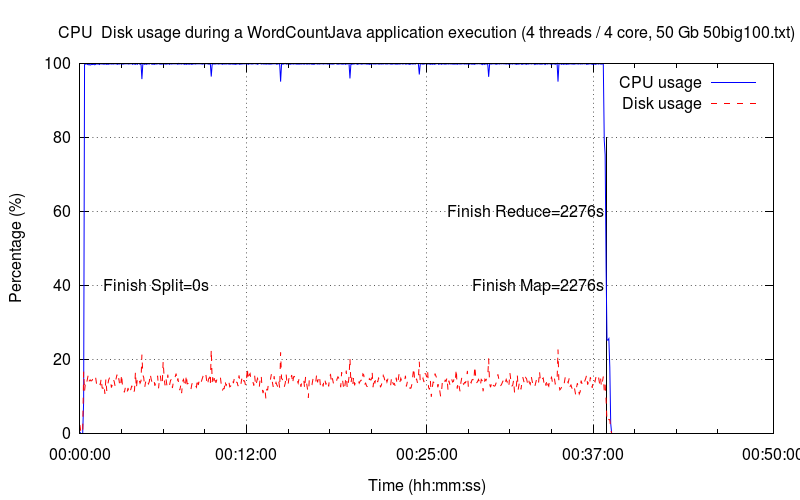
Ce quatrième graphique est sensiblement équivalent au précédent.
Cinq Threads▲
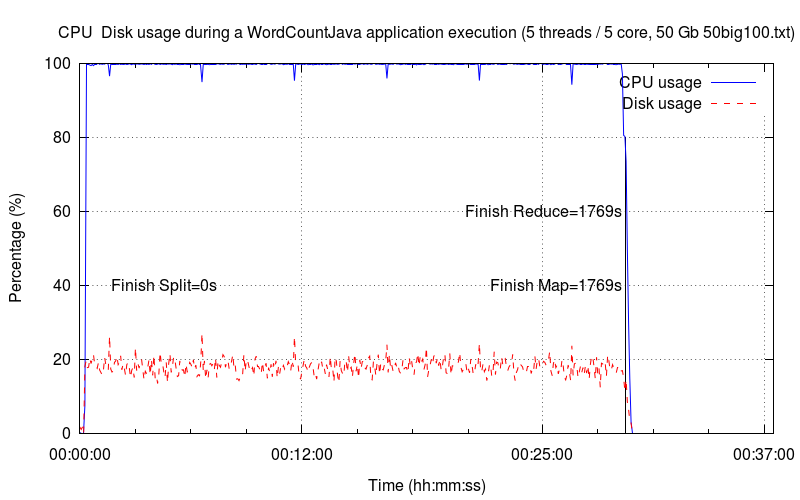
Le taux d'utilisation du disque augmente pour atteindre presque les 20 %.
Six Threads▲
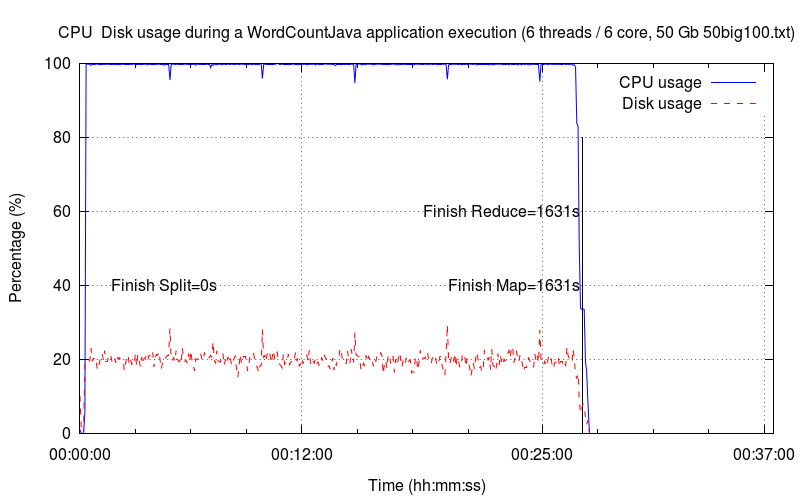
Ce dernier graphique est cohérent par rapport aux précédents. Le taux d'utilisation du disque dépasse les 20 %.
VI-B-2. Programme Hadoop▲
Le tableau ci-dessous présente les temps d'exécution du job MapReduce WordCount avec différents nombres de nœuds. Comme pour le programme Java ad hoc, la troisième ligne du tableau présente l'évolution par rapport à trois instances de nœuds qui est supposée être la configuration minimale d'un cluster Hadoop. Nous avons ajouté une ligne qui donne le temps moyen d'exécution d'une tâche de map. Cette information nous a été donnée par l'application JobHistoryJob MapReduce.
|
Nbre Nœud DataNode |
1 |
2 |
3 |
4 |
5 |
6 |
|---|---|---|---|---|---|---|
|
Temps exécution (hh:mm:ss) |
5h:24m:17s |
3h:23m:37s |
1h:48m:05s |
1h:11m:05s |
0h:54m:54s |
0h:49m:49s |
|
Évolution / à deux instances |
+0% |
-37% |
-47% |
-34% |
-24% |
-9.2% |
|
Temps moyen d'un map (mm:ss) |
45s |
47s |
51s |
54s |
57s |
01m:06s |
On remarque que tout naturellement le nombre de nœuds a une incidence sur le temps de résolution du job MapReduce.
Les sous-sections suivantes montrent les sollicitations du CPU et du disque dur pour des configurations de cluster différentes en termes de nombre de nœuds. Plus précisément pour chaque configuration de cluster, nous avons deux graphiques : un pour la sollicitation du CPU et un deuxième pour la sollicitation du disque dur. Pour chaque graphique, il y a autant de courbes que de nœuds sur le serveur (représentées par un trait continu) plus une courbe (représentée par une courbe pointillée noire) qui donne une moyenne du point de vue du cluster. Au temps 0, le job MapReduce est démarré pour la phase de map.
Un nœud DataNode▲
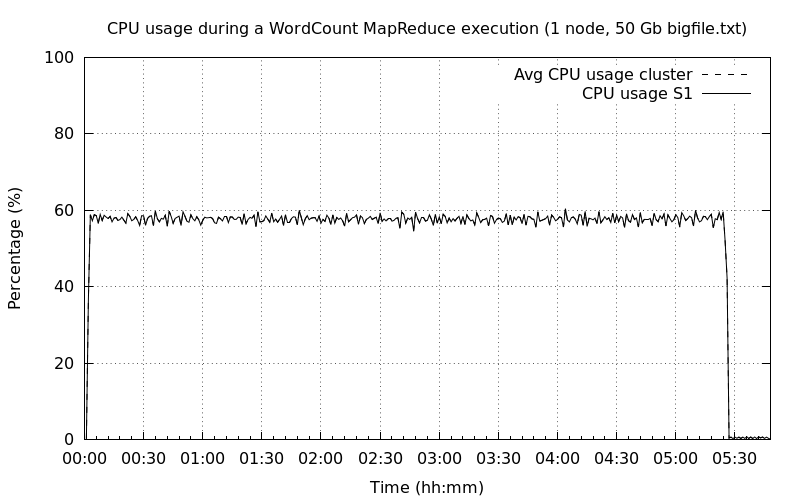
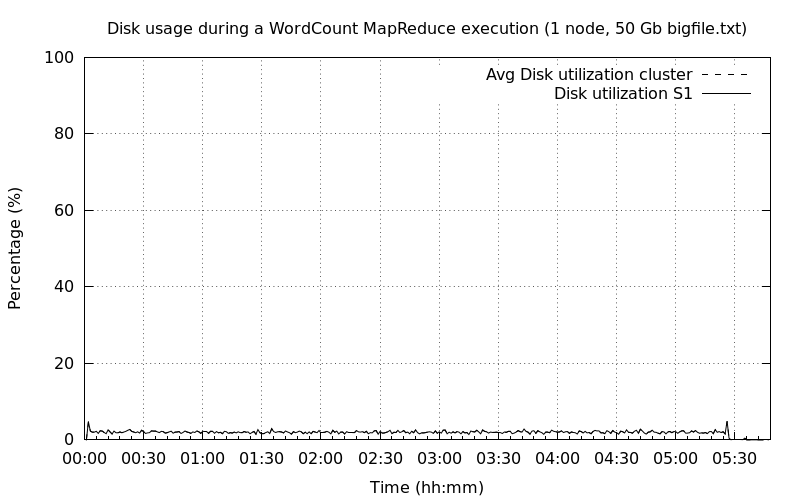
Petite surprise avec un seul nœud de type NameNode/DataNode, l'exécution du job MapReduce ne se lançait pas. J'ai un peu triché et j'ai mis en place un cluster avec deux nœuds dont le premier est un NameNode sans DataNode et le second est un DataNode exclusif.
La première exécution est très longue de l'ordre de plus de cinq heures. Ceci n'est pas surprenant sachant qu'une tâche map en moyenne est de 45 s et qu'il y a 470 tâches map à traiter. Une piste pour réduire le nombre de map serait d'augmenter la taille des blocs de données HDFS.
On constate également que le CPU n'est pas utilisé à son maximum de l'ordre de 60 % et que le disque n'est pas du tout sollicité ~ 3 %.
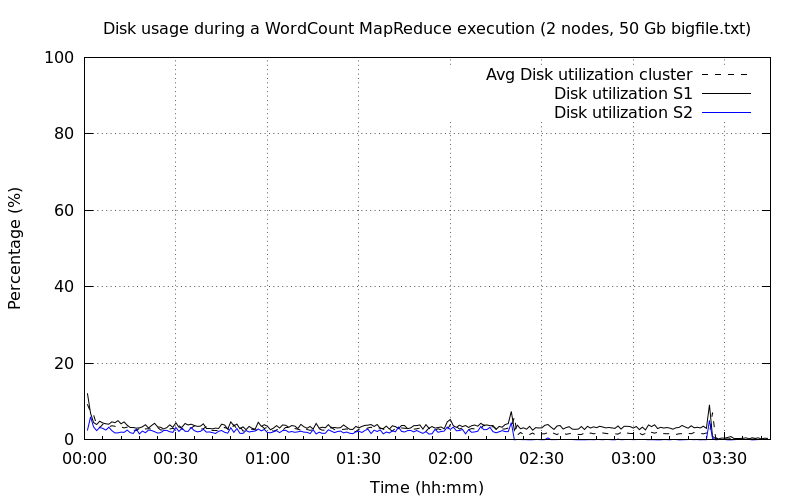
Deux nœuds DataNode▲
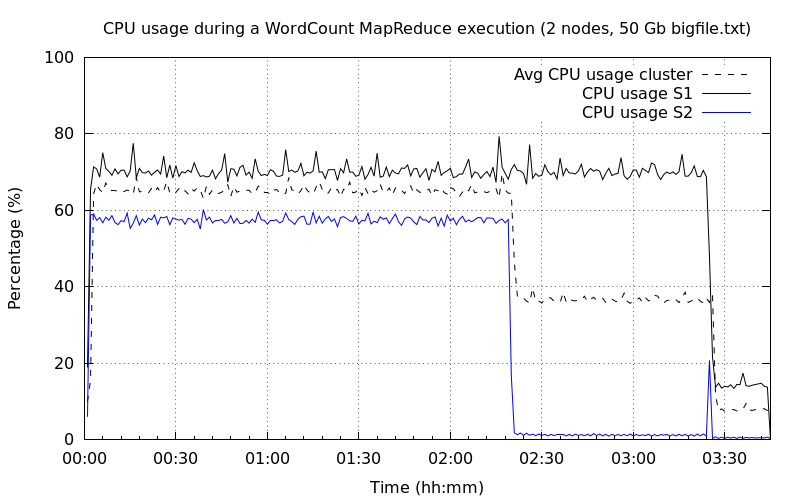
Avec deux nœuds DataNode, le temps d'exécution complet a été diminué de 37 %. L'utilisation du CPU est toujours de moitié pour les deux nœuds. On constate toutefois que l'occupation CPU du premier nœud est plus élevée de 10 % par rapport au second nœud. Cela s'explique par la présence sur le premier nœud des services spécifiques à Cloudera (Cloudera Manager, Hue, NameNode…).
On remarque au temps 2h:25m que l'utilisation CPU du second nœud est descendue au plus bas tandis que l'utilisation CPU du premier nœud continue. L'explication donnée est que les tâches map du second nœud se sont terminées plus tôt et ont continué pour le second nœud. Un pic sur le second nœud est identifié à la fin ce qui peut justifier les tâches reduce dont le nombre était de deux. Ainsi chaque nœud a terminé l'exécution par une phase reduce.
Pour finir, l'utilisation du disque est semblable à la première exécution.
Trois nœuds DataNode▲
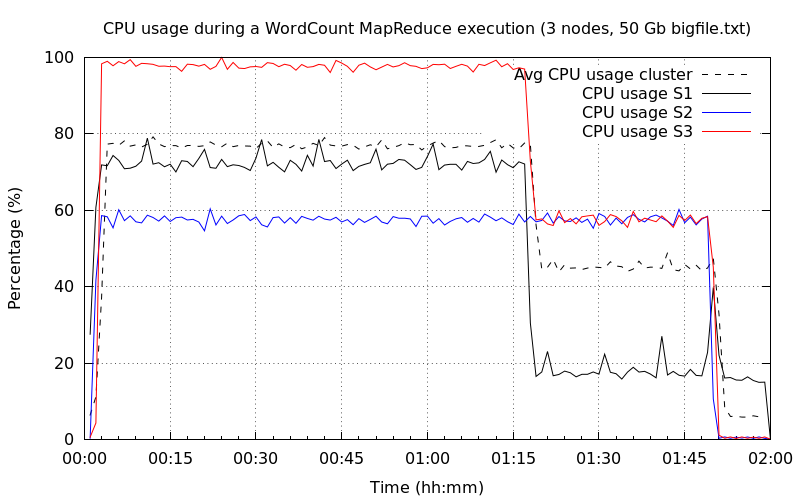
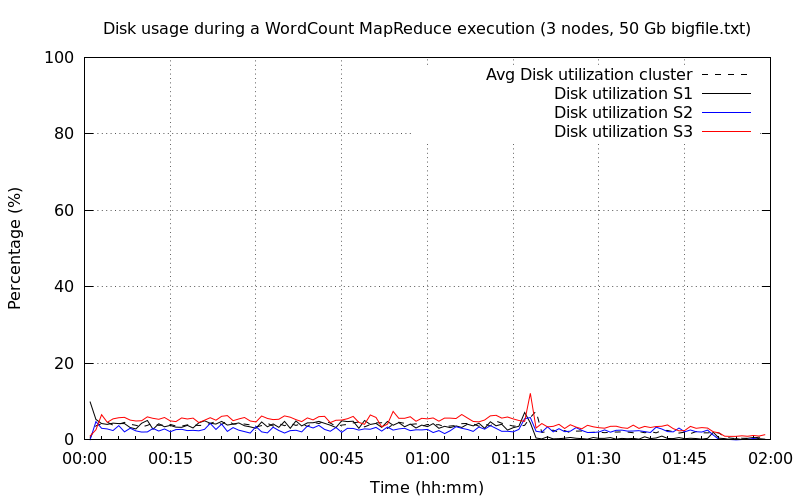
Le graphique de l'occupation CPU est proche du précédent. Nous noterons toutefois que la charge CPU du troisième nœud a atteint pratiquement 100 % pour descendre à une valeur identique au deuxième nœud vers 1h:20m. Vous remarquerez qu'à la fin de l'exécution 1h48m un pic de 20 %, il s'agit toujours de la tâche reduce. L'autre tâche reduce est menée par le troisième nœud.
Concernant l'utilisation du disque, on notera que pour le troisième nœud, le niveau est le plus haut.
Quatre nœuds DataNode▲
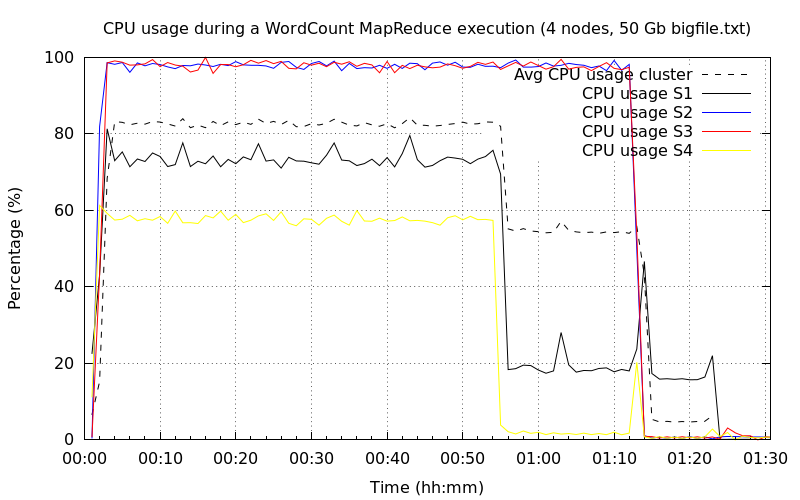

Il n'y a pas de grosse différence avec la précédente exécution. Les deuxième et troisième nœuds sont désormais au maximum de l'occupation CPU.
Concernant l'utilisation du disque, c'est toujours très bas, il n'est pas du tout sollicité.
Cinq nœuds DataNode▲
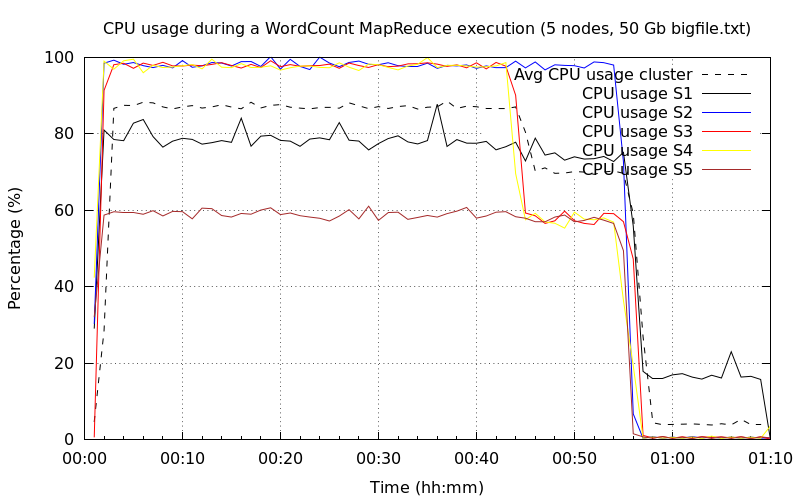
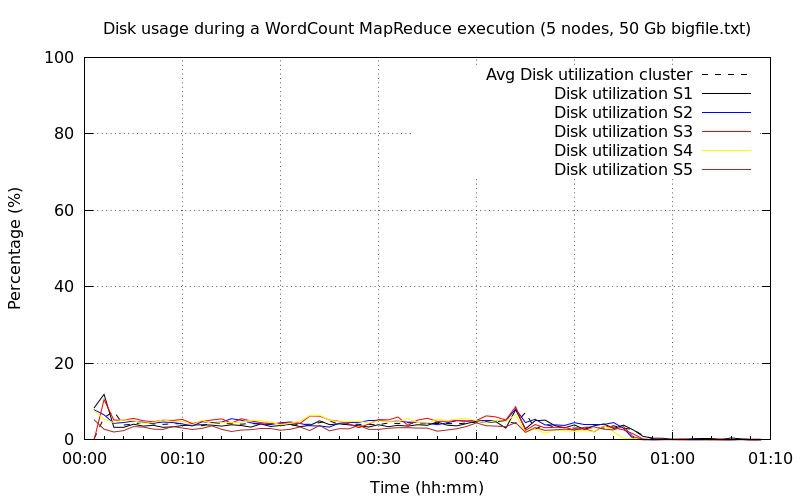
Pas de différence sur l'occupation CPU, hormis le fait que maintenant trois nœuds sont à 100 %.
L'utilisation du disque est toujours identique aux précédents et cela ne changera pas pour la suite, car on a clairement identifié que le CPU était le facteur limitant.
Six nœuds DataNode▲
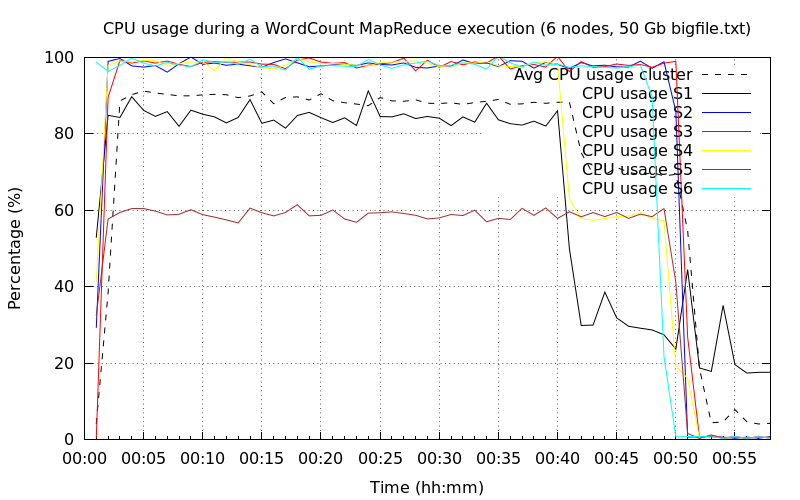
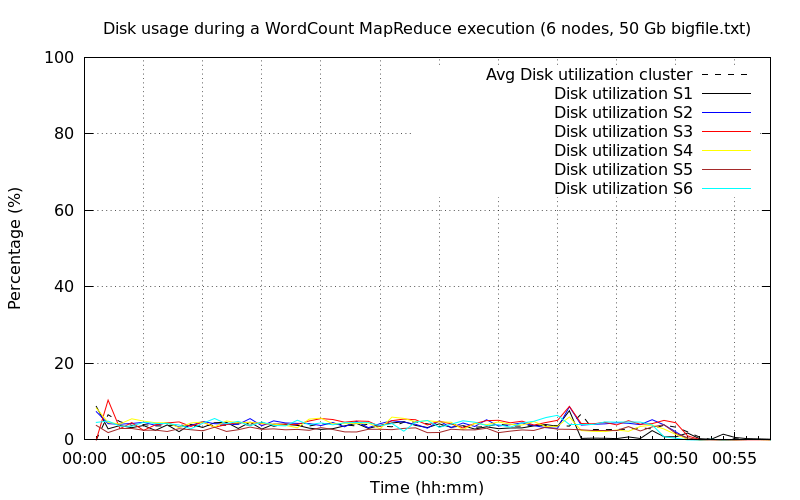
L'exécution est descendue sous la barre des une heure. Nous avons toujours deux nœuds qui ne sont pas totalement sollicités. Une explication plausible viendrait de la tâche reduce. Comme elles sont au nombre de deux, Hadoop réserve deux nœuds pour accomplir les tâches. Par ailleurs, d'après les configurations dans le fichier mapred-default.xml, le paramètre mapreduce.reduce.cpu.vcores spécifie le nombre de cœurs qui est fixé à 1 par défaut. Par conséquent comme nos machines virtuelles sont configurées avec deux cœurs virtuels, Hadoop n'allouerait pour les deux nœuds qu'un seul cœur à chaque fois pour les tâches map.
VII. Bilan et perspectives▲
Intéressons-nous à réaliser une conclusion sous forme de bilan des exécutions du programme ad hoc Java et du job MapReduce. Le graphique ci-dessous résume bien nos expérimentations en termes de temps d'exécution. Dans les deux cas, nous avons identifié que l'occupation CPU était le facteur limitant des exécutions. Le programme Java ad hoc de comptage de mots est plus efficace que son homologue job MapReduce, c'est une évidence. Toutefois, il faut nuancer ces résultats, n'enterrons pas tout de suite la technologie Hadoop sur le simple critère du temps d'exécution.
Tout d'abord, les architectures matérielles employées par les programmes ont une évolution différente. En effet avec une scalabilité verticale, celle utilisée pour le programme Java ad hoc, les limites seront vite atteintes par le nombre de cœurs, la taille mémoire et la taille du disque dur. Au contraire, Hadoop fournit une solution extensible qui permet d'augmenter considérablement le nombre de nœuds, exemple : 42 000 nœuds chez Yahoo.
Ensuite, Hadoop fournit un framework de développement. Le développeur n'a pas à se soucier de la manière de comment seront gérés les différents nœuds, le framework s'en occupe. Le développeur se focalisera sur sa tâche de map et de reduce.
Par ailleurs, nos expérimentations ont porté sur un petit jeu de données, non représentatif de ce qui pourrait être traité par une solution BigData comme Apache Hadoop. Il faudrait augmenter la taille des données pour vraiment apprécier des capacités de Apache Hadoop.
Enfin, l'occupation CPU a été identifiée comme un facteur limitant durant toutes nos expérimentations. L'augmentation des performances du processeur (nombre de nœuds et choix d'un meilleur processeur) serait une solution.
Concernant les perspectives de ces expérimentations et comme dit juste en haut, il faudrait reprendre celles concernant Hadoop afin d'augmenter principalement la taille des données et le nombre de nœuds. Il faudrait voir également si d'autres facteurs limitants entrent en jeu comme le débit du réseau.
VIII. Conclusion, à suivre dans le prochain article▲
Dans cet article nous nous sommes intéressés d'une part à l'installation et la configuration d'un cluster Apache Hadoop multinœud et d'autre part à l'exécution d'un job MapReduce dans ce même cluster. Afin de montrer l'avantage de l'architecture matérielle que supporte Apache Hadoop, nous avons eu à comparer l'exécution d'un job MapReduce avec celle d'un simple programme Java. Certes le programme Java ad hoc est plus efficace mais le framework Hadoop fournit un cadre très simple pour gérer la programmation distribuée.
Nous verrons dans le prochain tutoriel le développement d'algorithmes MapReduce via différentes études de cas.
Je tiens à remercier Claude Leloup pour sa relecture orthographique attentive de cet article.
IX. Ressources▲
- Documentation Cloudera Manager : http://www.cloudera.com/content/cloudera/en/documentation/core/latest/cloudera-homepage.html
- Dépôt GitHub pour le programme Java ad hoc de comptage de mots : https://github.com/mickaelbaron/wordcountjava
- Dépôt GitHub pour le benchmark basé sur le programme Java de comptage de mots : https://github.com/mickaelbaron/wordcountjavabench
- Dépôt GitHub pour le script de génération de graphiques à partir des services Rest Cloudera : https://github.com/mickaelbaron/clouderamanagerapi-gnuplot
