




I. Présentation Cassandra▲
Nous décrivons dans cette section, qui se veut être une introduction, les grandes lignes d'Apache Cassandra.
Nous discuterons dans un premier temps de l'origine de Cassandra puis nous parlerons des caractéristiques de cette base de données NoSQL. Nous traiterons ensuite de son modèle de données spécifique et nous terminerons par les principaux cas d'usage.
À noter que nous tenterons lors des explications de réaliser un parallèle entre Cassandra et les bases de données relationnelles.
N'hésitez pas à consulter ce glossaire. Il contient une explication des nombreux concepts utilisés dans Cassandra.
Enfin, cette introduction ne se veut pas être exhaustive, nous reviendrons plus en détail sur Cassandra dans les prochains articles. N'hésitez pas non plus à consulter les liens fournis à la fin de cet article si vous souhaitez des compléments d'information.
I-A. Origine▲
Pour la petite histoire, dans la mythologie grecque, Cassandra était la fille du roi de Troie, d'une très grande beauté. Apollon, dieu grec du chant, de la musique et de la poésie, charmé par sa beauté lui fit don de prophétie en échange de futurs ébats. Cassandra accepta le don, mais se refusa à lui. En représailles celui-ci lui retira le pouvoir de persuasion malgré sa capacité de voyance (d'où le logo). Vous retrouverez une histoire complète sur le site de Wikipedia.

Dans le projet de la fondation Apache, Cassandra est une base de données distribuée qui permet de stocker une grande quantité de données grâce à sa scalabilité horizontale. Ce terme correspond à la possibilité offerte par l'architecture Cassandra d'ajouter de nouvelles machines qui sont appelées des nœuds. Les machines utilisées sont généralement des machines dites Community hardware c'est-à-dire qu'elles correspondent au meilleur rapport/qualité prix.
Initialement Cassandra a été développée en interne par Facebook pour les besoins de sa messagerie interne (lien 1 et lien 2). L'utilisation de Cassandra était limitée aux exigences de sa messagerie. Par conséquent de nombreuses fonctionnalités n'étaient pas implémentées puisqu'elles n'étaient pas nécessaires. En 2008, Facebook décide d'offrir Cassandra à la fondation Apache. Le projet est resté deux ans dans l'incubateur avant de devenir projet à part entière (dit "top-level projects") de la fondation Apache en 2010. Vous trouverez sur le site d'Apache (http://cassandra.apache.org/) de nombreuses ressources via un WIKI et des versions à télécharger. Les principaux contributeurs au projet sont issus de la société DataStax. Celle-ci cofondée par Johnatan Ellis, le project chair de Casandra, s'occupe de fournir du support et un écosystème autour de Cassandra.
Concernant les utilisateurs de Cassandra, nous retrouvons les grands acteurs du Web tels que Netflix, Spotify, eBay ou Twitter. Une liste non exhaustive est disponible sur le site de DataStax (http://planetcassandra.org/Company/ViewCompany?IndustryId=-1).
I-B. Principales caractéristiques▲
Nous détaillons dans cette section les principales caractéristiques de la base de données NoSQL Cassandra.
- Tolérance aux pannes : les données d'un nœud (un nœud est une instance de Cassandra) sont automatiquement répliquées vers d'autres nœuds (différentes machines). Ainsi, si un nœud est hors service les données présentes sont disponibles à travers d'autres nœuds. Le terme de facteur de réplication désigne le nombre de nœuds où la donnée est répliquée. Par ailleurs, l'architecture de Cassandra définit le terme de cluster comme étant un groupe d'au moins deux nœuds et un data center comme étant des clusters délocalisés. Cassandra permet d'assurer la réplication à travers différents data center. Les nœuds qui sont tombés peuvent être remplacés sans indisponibilité du service.
- Décentralisé : dans un cluster tous les nœuds sont égaux. Il n'y pas de notion de maitre, ni d'esclave, ni de processus qui aurait à sa charge la gestion, ni même de goulet d'étranglement au niveau de la partie réseau. Nous étudierons dans un prochain article lié à la scalabilité le protocole GOSSIP utilisé pour découvrir la localisation et les informations sur l'état des nœuds d'un cluster.
- Modèle de données riche : le modèle de données proposé par Cassandra basé sur la notion de clé/valeur permet de développer de nombreux cas d'utilisation dans le monde du Web.
- Élastique : la scalabilité est linéaire. Le débit d'écriture et de lecture augmente de façon linéaire lorsqu'un nouveau serveur est ajouté dans le cluster. Par ailleurs, Cassandra assure qu'il n'y aura pas d'indisponibilité du système ni d'interruption au niveau des applications.
- Haute disponibilité : possibilité de spécifier le niveau de cohérence concernant la lecture et l'écriture. On parle alors de Tuneable Consistency. Apache Cassandra ne dispose pas de transaction. L'écriture des données est très rapide comparée au monde des bases de données relationnelles.
I-C. Modèle de données▲
Dans les applications du monde du Web, type Facebook par exemple, les données ne sont pas décrites de la même façon. L'utilisation des bases de données relationnelles n'est pas toujours appropriée. En effet cela conduirait à stocker des données avec de nombreuses valeurs nulles. C'est dans cet objectif que des modèles de données proches de celui de Cassandra ont été développés.
Par ailleurs, dans une base de données relationnelle classique, il est d'usage de normaliser les données afin d'éviter la redondance des données et les problèmes inhérents liés aux mises à jour. Les données sont ainsi structurées d'une certaine façon qui implique à la lecture de passer par des jointures pour obtenir les résultats souhaités. Apache Cassandra du fait de son caractère décentralisé sur plusieurs machines ne le permet pas. L'idée de faire une jointure sur plusieurs machines n'aurait alors aucun sens. Au contraire Apache Cassandra va vous obliger à dénormaliser un maximum. Ainsi, le gros du travail sur les données se fera pendant la phase d'écriture. Pour cela, les données sont alors regroupées dans des familles de colonnes (column families). Par conséquent lors de la conception de votre base de données sur Apache Cassandra, vous aurez plus tendance à concevoir votre modèle de données en fonction des requêtes que vous souhaitez faire. La manière d'écrire des données se fera donc pour assurer une meilleure lecture.
Initialement basée sur Big Table de Google, Apache Cassandra stocke les données dans une suite triée de couples clé/valeur. On classifie ainsi Cassandra comme une base de données NoSQL orientée colonne sans aller jusqu'au stockage physique en colonne.
Dans la suite de cette section, nous étudions les principaux concepts du modèle de données utilisé par Apache Cassandra.
I-C-1. Colonne▲

Une colonne est la plus petite unité du modèle de données de Cassandra. C'est un triplet contenant un nom, une valeur et un timestamp. Ce dernier sert à déterminer la mise à jour la plus récente. La taille du nom peut être contenue jusqu'à 64 KO. La valeur quant à elle peut contenir 2 GO de données.
La valeur n'est pas obligatoire. Son omission peut conduire à une amélioration de performance. Le nom de la colonne peut être considéré comme une valeur. Par exemple sur la figure ci-dessous, le nom de la colonne contient le nom de l'utilisateur et un score.
La case valeur peut contenir plusieurs valeurs. C'est le cas par exemple d'une collection de chaînes de caractères.

Une colonne a un type appelé comparator. Une valeur a également un type appelé validator. Nous listons sur le tableau ci-dessous les différents types proposés. Nous montrons deux colonnes. Une première relative au type natif utilisé en interne et une seconde plus propice à une utilisation pour le langage CQL (Cassandra Query Language).
| Type Interne | Nom CQL |
| BytesType | blob |
| AsciiType | ascii |
| UTF8Type | text, varchar |
| IntegerType | varint |
| Int32Type | int |
| LongType | bigint |
| UUIDType | uuid |
| TimeUUIDType | timeuuid |
| DateType | timestamp |
| BooleanType | boolean |
| FloatType | float |
| DoubleType | double |
| DecimalType | decimal |
| CounterColumnType | counter |
Nous reviendrons dans le deuxième article consacré au modèle de données afin d'étudier plus précisément les colonnes de type Expiring Column, Counter Column, Tombstone…
I-C-2. Ligne▲
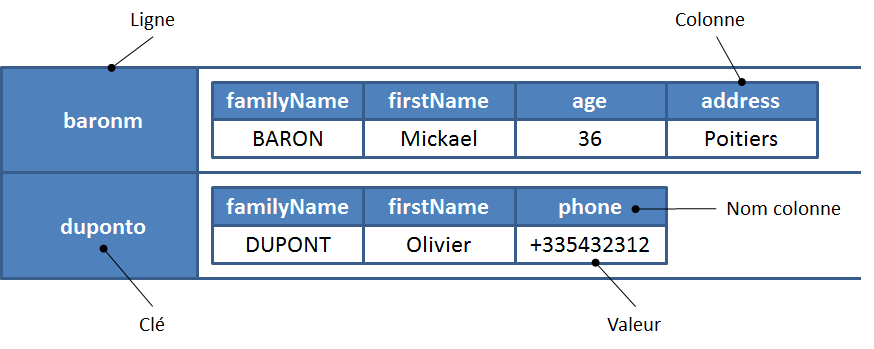
Une ligne est composée d'un ensemble de colonnes. Elle est identifiée par une clé. Une clé peut contenir jusqu'à 64 Ko de données et peut contenir jusqu'à deux milliards de colonnes. Il est possible d'utiliser des colonnes comme clé primaire.
Nous montrons sur la figure ci-dessous un exemple de deux lignes. Notez 1) que le nombre de colonnes n'est pas identique et 2) que les colonnes ne sont pas forcément les mêmes.
I-C-3. Famille de colonnes (Column Family)▲
Une famille de colonnes ou column family en anglais est un regroupement logique de lignes. Pour faire le parallèle avec le monde des bases de données relationnelles, une famille de colonnes est en quelque sorte une table.

Lors de la définition d'une famille de colonnes, vous pouvez y ajouter des informations concernant les métadonnées des colonnes. Ces informations peuvent être utilisées pour renseigner le nom et le type des colonnes. Toutefois c'est au moment de l'ajout d'une ligne que vous choisirez quelles sont les colonnes à exploiter.
C'est ainsi que Cassandra distingue deux types de famille de colonnes :
- statique : les colonnes sont définies lors de la création ou modification de la famille de colonnes ;
- dynamique : les colonnes sont définies lors de la création ou modification d'une ligne.
I-C-4. Keyspace▲
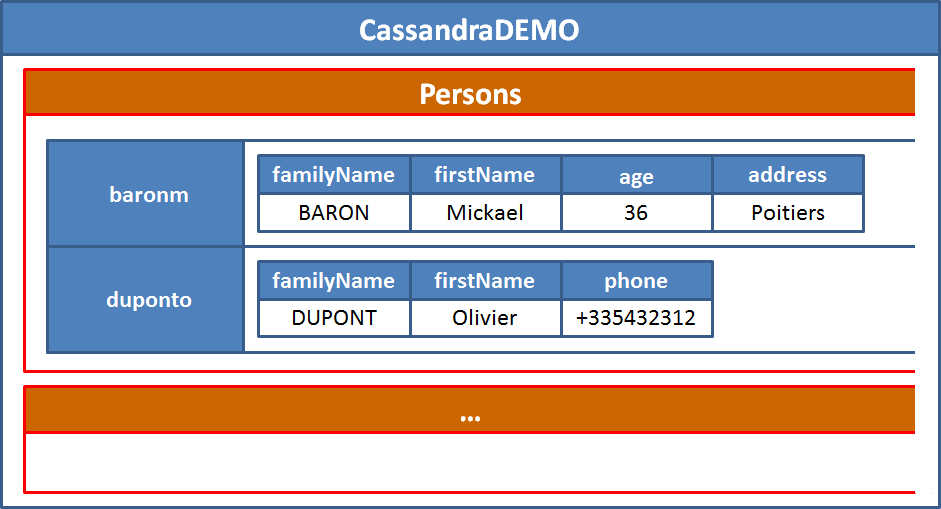
Finalement le Keyspace est un regroupement de famille de colonnes. Il s'agit d'une sorte de schéma si on compare au monde des bases de données relationnelles.
I-D. Quand utiliser Cassandra ?▲
Vous utiliserez Apache Cassandra à chaque fois que vous aurez affaire à une problématique de charge, de volume et de besoins de très haute disponibilité.
Les cas d'utilisation sont très nombreux. Pour ne citer que les plus importants, on peut noter :
- Timeseries : où les données sont stockées suivant des timestamps. Une modélisation possible serait d'utiliser le nom de la colonne comme timestamp et la valeur contiendrait les données. Les logs ou les données issues de capteurs s'y prêtent parfaitement.
- Clickstreams : l'enregistrement des actions d'un utilisateur sur application.
II. Télécharger Cassandra▲
Pour les besoins de cette série d'articles, j'utiliserai la version 1.2 afin de disposer des dernières fonctionnalités offertes par le langage CQL 3.
Apache Cassandra peut être téléchargée à partir du site d'Apache ou directement sur le site de DataStax.
- Via le site Apache : vous disposerez alors d'une solution minimale qui ne contiendra que la base de données Cassandra. Le fichier d'installation se limitera à une archive ZIP qu'il faudra décompresser. Il vous sera ensuite demandé de configurer certains fichiers.
- Via le site de DataStax : vous trouverez alors deux distributions. La première appelée DataStax Entreprise Edition, payante, fournit la dernière version de Cassandra, l'outil d'administration OpsCenter et une multitude de services et de fonctionnalités pour utiliser Cassandra en production. La seconde appelée DataStax Community Edition, gratuite, fournit la dernière version de Cassandra et l'outil d'administration OpsCenter. Un comparatif des différentes distributions est disponible à cette adresse.
Nous utiliserons les deux types installation.
En effet, au niveau de la section , la distribution DataStax Community Edition sera utilisée afin de présenter l'outil d'administration OpsCenter.
De même dans le reste de l'article, la version proposée par Apache sera utilisée afin de manipuler explicitement la configuration de Cassandra. En effet, bien que l'automatisation de l'installation fournie par DataStax facilite le déploiement de Cassandra, il est toujours intéressant pour une bonne administration de comprendre où et comment paramétrer certains services (exemples : les logs et le répertoire de données).
Pour les besoins de l'article, téléchargez la distribution depuis : http://apache.mirrors.multidist.eu/cassandra/.
III. Installation et Configuration▲
L'installation se fera sous Windows 7 64 Bits. Vous pouvez bien entendu adapter cette installation suivant votre système d'exploitation tant que celui-ci à mon avis supporte l'installation d'une JRE.
III-A. Prérequis▲
Veuillez vous assurer que vous disposez d'une machine virtuelle Java. De mon côté un JDK 6 Update 35 en 32 Bits est installé.
Veuillez également vous assurer que les variables d'environnement JAVA_HOME pointent sur le répertoire de votre JDK (exemple : C:\Program Files (x86)\Java\jdk1.6.0_35) et que PATH contient le répertoire BIN de votre JDK (exemple : %PATH%;C:\Program Files (x86)\Java\jdk1.6.0_35\bin).
III-B. Installation▲
Décompressez l'archive téléchargée précédemment dans le répertoire C:\Program Files (x86)\apache-cassandra-1.2.0-beta2.
Nous remarquons la structure suivante très proche des outils fournis par Apache (Maven, Tomcat…) :
- bin : contient les scripts d'exécution. Vous y trouverez principalement le script de démarrage de Cassandra (cassandra.bat), le script pour démarrer le client en ligne de commande (cassandra-cli.bat), un script Python pour le client CQL (cqlsh), un script pour l'administration d'un cluster (nodetool.bat) ;
- conf : contient les fichiers de configuration pour Cassandra. Vous y trouverez principalement le fichier cassandra.yaml dédié à la configuration de Cassandra et le fichier log4j-server.properties dédié à la configuration des messages logs ;
- interface : contient la configuration pour Thrift qui assure l'intéropérabilité entre Apache Cassandra et les API clientes. Ainsi grâce à Thrift, Cassandra offre de nombreux connecteurs vers des clients de différents langages (C#, PHP, Java, C++…) ;
- javadoc : contient la JavaDoc de Cassandra ;
- lib : contient les bibliothèques nécessaires à l'exécution d'Apache Cassandra ;
- pylib : contient les bibliothèques Python pour Thrift ;
- tools : contient des outils tiers et notamment l'outil Cassandra-Stress (cassandra-stress.bat) idéal pour effectuer des benchmarks sur son cluster.
Afin de pouvoir profiter des outils basés sur des scripts Python (exemple cqlsh), veuillez installer Python 2.7.3 (http://www.python.org/ftp/python/2.7.3/python-2.7.3.msi). Assurez-vous également d'ajouter le chemin du répertoire de Python dans la variable PATH (dans mon cas c'est C:\Program Files (x86)\Python2.7.3).
III-C. Configuration▲
Dans un premier temps, ajoutez dans la variable PATH, le chemin du répertoire BIN de Cassandra (dans mon cas c'est C:\Program Files (x86)\apache-cassandra-1.2.0-beta2\bin).
Depuis le fichier de configuration conf/cassandra.yaml, modifiez les entrées suivantes :
- data_file_directories : précise le répertoire où Cassandra stockera les données sur le disque. Pour mon installation, la valeur choisie est D:/workspacePOCNoSQL/CassandraData/data ;
- commitlog_directory : la valeur choisie est D:/workspacePOCNoSQL/CassandraData/commitlog ;
- saved_caches_directory : la valeur choisie est D:/workspacePOCNoSQL/CassandraData/saved_caches.
Pour les répertoires de configuration, assurez-vous qu'ils existent et que l'écriture est autorisée.
La configuration pour les logs est définie dans le fichier log4j-server.properties. Vous pouvez par exemple préciser le fichier d'écriture des messages via l'entrée log4j.appender.R.File qui dans mon cas prend la valeur D:/workspacePOCNoSQL/CassandraData/system.log.
De nombreux autres paramètres sont disponibles, vous trouverez des informations complémentaires sur le site d'Apache et sur le site de DataStax.
Afin de vérifier que votre installation est correcte, démarrez Apache Cassandra en ouvrant une invite de commande et en saisissant cassandra.bat. Vous devriez alors obtenir le résultat suivant :
À noter que pour arrêter Cassandra sous Windows, il vous suffira de faire un simple Control-C.
III-D. Créer un service Windows▲
Si vous souhaitez démarrer Apache Cassandra via un service Windows, le script cassandra.bat le prévoit. Il vous faudra par contre installer l'outil Procrun fourni par la fondation Apache. Cet outil se charge de créer des services Windows pour les applications Java. Il crée en quelque sorte un wrapper pour les applications Java (Tomcat par exemple).
Téléchargez la distribution native (sous forme d'exécutable Windows) sur le site d'Apache. Créez obligatoirement un répertoire daemon à la racine du répertoire %CASSANDRA_HOME%\bin puis déposez-y le fichier prunsrv.exe. Ouvrez ensuite une invite de commande Windows puis saisissez la commande suivante cassandra.bat install. Si tout s'est bien déroulé, vous devriez avoir un nouveau service appelé cassandra depuis le gestionnaire de services de Windows.
IV. Premiers pas▲
L'objectif de cette section est de montrer comment manipuler une base de données Cassandra via deux outils en ligne de commande. Nous retrouvons tout d'abord l'outil Cassandra-CLI qui historiquement était le premier outil à pouvoir attaquer une base de données Cassandra. Puis, avec l'arrivée du langage de requêtes CQL, un second outil basé sur Python est apparu CQLSH.
Pour faire le parallèle avec le monde des bases de données relationnelles, cqlsh est l'équivalent de psql en PostgreSQL ou mysql en MySQL.
Par conséquent pour chaque type d'opération (création, interrogation, suppression et modification) sur les concepts-clés (keyspace, famille de colonnes et ligne) d'une base de données Cassandra nous montrerons des exemples de lignes de commande via ces deux outils.
Comme nous exécutons Cassandra en local, nous utiliserons les paramètres par défaut des deux outils (localhost et port 9160 par défaut). Les outils ont la possibilité de se connecter via une base de données Cassandra située sur un autre serveur via des ports différents.
- Démarrer l'outil Cassandra CLI : cassandra-cli.bat
- Démarrer l'outil CQLSH : python cqlsh
Cette section ne se veut pas être une présentation exhaustive des commandes disponibles. N'oubliez pas de consulter la documentation de référence de Cassandra afin d'obtenir des informations supplémentaires. Par ailleurs, au niveau des deux outils Cassandra-CLI et CQLSH, vous pouvez obtenir des informations sur chacune des commandes en exécutant cette commande help 'command';.
IV-A. Opérations sur les Keyspace▲
Cette section montre toutes les opérations nécessaires à la création, l'interrogation, la modification et la suppression d'un KEYSPACE. Pour rappel, un KEYSPACE regroupe tout un ensemble de familles de colonnes.
IV-A-1. Création▲
Ci-dessous, nous créons un KEYSPACE appelé cassandrademocli ou cassandrademocql via la commande CREATE KEYSPACE, en utilisant la stratégie de placement 'SimpleStrategy' et un facteur de réplication à 1.
Cassandra CLI
CREATE KEYSPACE cassandrademocli WITH placement_strategy = 'SimpleStrategy' AND strategy_options = {replication_factor:1};CQLSH
CREATE KEYSPACE cassandrademocql WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : 1 };Un KEYSPACE ne peut être appelé system puisqu'il existe un métaKEYSPACE qui porte ce nom.
Afin de pouvoir agir sur un KEYSPACE et par conséquent sur ses familles de colonnes, il faut indiquer explicitement que vous souhaitez l'utiliser en employant la commande USE KEYSPACE.
Cassandra CLI
USE cassandrademocli;CQLSH
USE cassandrademocql;L'utilisation de la commande USE n'est pas obligatoire. Vous pouvez préfixer sur certaines commandes les familles de colonnes par le KEYSPACE de cette manière : keyspace.columnFamily.
IV-A-2. Interrogation▲
L'interrogation permet d'obtenir la liste des KEYSPACE disponibles d'une base de données Cassandra.
Les commandes sont différentes selon que vous utilisez Cassandra-CLI ou CQLSH. Le résultat de l'exécution est donné sur la ligne suivante.
Cassandra CLI
SHOW keyspaces;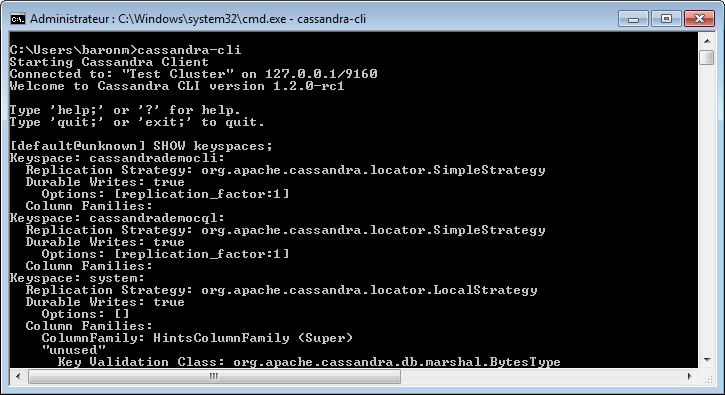
CQLSH
SELECT * FROM system.schema_keyspaces;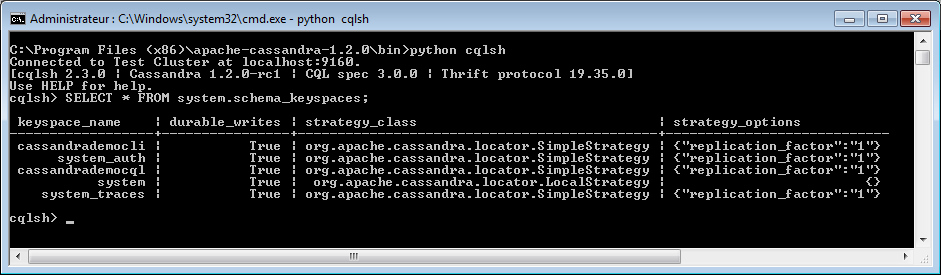
Vous remarquerez que dans le cas de CQL il n'existe pas de commande clés en main. La solution consiste à passer par le métaKEYSPACE appelé system et d'interroger la famille de colonnes appelée schema_keyspaces.
IV-A-3. Modification▲
La modification d'un KEYSPACE permet de paramétrer certaines options comme la stratégie de placement ou le facteur de réplication. Le renommage d'un KEYSPACE n'est pas encore supporté.
Cassandra CLI
UPDATE KEYSPACE cassandrademocli WITH strategy_options = {replication_factor:2};CQLSH
ALTER KEYSPACE cassandrademocql WITH strategy_class=SimpleStrategy AND strategy_options:replication_factor=1;Dans le cas de CQL, j'ai constaté un problème sur l'exécution de la requête via la commande ALTER KEYSPACE à partir du moment où l'on souhaite modifier la colonne strategy_options.
IV-A-4. Suppression▲
Les commandes de suppression d'un KEYSPACE sont identiques pour les deux outils. Elles sont décrites dans le tableau ci-dessous.
Cassandra CLI
DROP KEYSPACE cassandrademocli;CQLSH
DROP KEYSPACE cassandrademocql;IV-B. Opérations sur les familles de colonnes (Column Family)▲
Cette section montre toutes les opérations nécessaires à la création, l'interrogation, la modification ou la suppression d'une famille de colonnes (Column Family). Pour rappel, une famille de colonnes peut être vue comme une table dans le monde des bases de données relationnelles. Il s'agit d'un conteneur de lignes.
IV-B-1. Création▲
Nous présentons ci-dessous les commandes de création d'une famille de colonnes dans le cas d'une famille de colonnes statique.
Cassandra CLI
CREATE COLUMN FAMILY Persons
WITH comparator = UTF8Type
AND key_validation_class=UTF8Type
AND column_metadata = [
{column_name:familyName, validation_class: UTF8Type}
{column_name:firstName, validation_class: UTF8Type}
{column_name:age, validation_class: Int32Type}
{column_name:address, validation_class: UTF8Type}
];CQLSH
CREATE TABLE Persons (
familyName varchar,
firstName varchar,
age int,
address varchar,
PRIMARY KEY(familyName));IV-B-2. Interrogation▲
L'interrogation permet d'obtenir les métadonnées d'une famille de colonnes quand celle-ci est définie de manière statique. Elle permet par exemple d'extraire les informations des colonnes (nom, type…).
Cassandra CLI
SHOW keyspaces;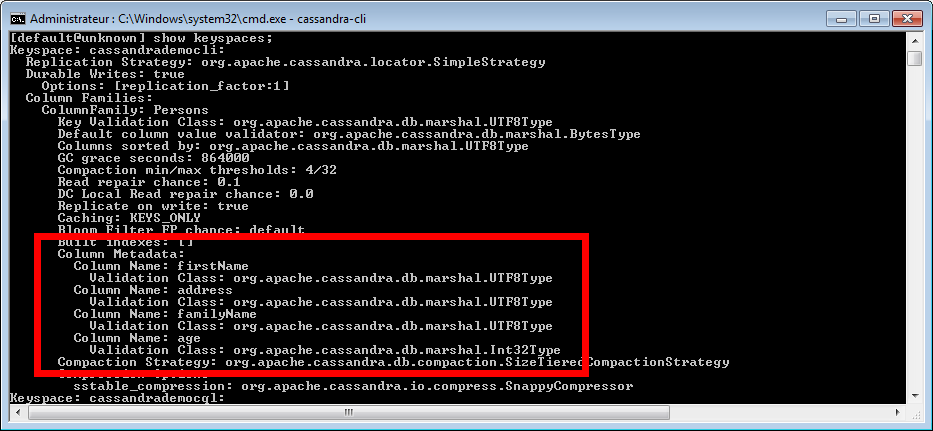
Il n'existe pas de commande spécifique pour obtenir ce type d'information. Toutefois la commande liée à l'interrogation du KEYSPACE, étudiée précédemment, peut suffire à obtenir ces informations.
CQLSH
SELECT columnfamily_name FROM schema_columnfamilies WHERE keyspace_name = 'cassandrademocql';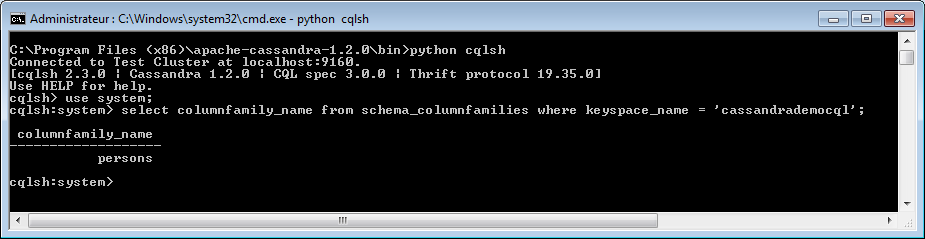
Du côté de la requête CQL, il faut passer par le méta KEYSPACE system et d'interroger la famille de colonne appelée schema_columnfamilies. Vous pouvez également interroger la famille de colonnes schema_columnfamilies plus complet pour obtenir des informations spécifiques à une famille de colonnes.
SELECT column_name FROM schema_columns WHERE keyspace_name = 'cassandrademocql' and columnfamily_name = 'persons';
La requête ci-dessus montre comment récupérer les colonnes d'une famille de colonne. Il faut toujours passer par le méta KEYSPACE system et interroger cette fois-ci la famille de colonne appelée schema_columns.
IV-B-3. Modification▲
La modification permet de manipuler les métadonnées d'une famille de colonnes. Il vous sera alors possible de :
- modifier le type d'une colonne ;
- ajouter une nouvelle colonne ;
- supprimer une colonne existante ;
- modifier des propriétés d'une colonne.
Nous nous limiterons à l'ajout d'une nouvelle colonne, par exemple une colonne phone de type chaîne de caractères.
Cassandra CLI
UPDATE COLUMN FAMILY Persons WITH column_metadata = [
{column_name:familyName, validation_class: UTF8Type}
{column_name:firstName, validation_class: UTF8Type}
{column_name:age, validation_class: Int32Type}
{column_name:address, validation_class: UTF8Type}
{column_name:phone, validation_class: UTF8Type}
];CQLSH
ALTER TABLE Persons ADD phone VARCHAR;Vous remarquerez qu'au niveau de CASSANDRA CLI, l'ajout d'une nouvelle colonne se fait en redéfinissant complètement la valeur de la colonne column_metadata.
IV-B-4. Suppression▲
Cette opération supprime une famille de colonnes à partir d'un nom.
Cassandra CLI
DROP COLUMN FAMILY Persons;CQLSH
DROP COLUMNFAMILY Persons;IV-C. Opérations sur les lignes▲
Nous montrons dans cette section toutes les opérations nécessaires à la manipulation de lignes au niveau d'une famille de colonnes. À titre de comparaison, cela revient à manipuler les lignes d'une table dans le monde des bases de données relationnelles.
IV-C-1. Création▲
La création consiste à ajouter une nouvelle ligne dans une famille de colonnes.
Cassandra CLI
USE cassandrademocli;
SET Persons['mbaron']['familyName']='BARON';
SET Persons['mbaron']['firstName']='Mickael';
SET Persons['mbaron']['age']=36;
SET Persons['mbaron']['address']='Poitiers';
SET Persons['mbaron']['phone']='+33549498073';CQLSH
USE cassandrademocql;
INSERT INTO Persons (familyName, firstName, age, address,phone) VALUES ('BARON', 'Mickael', 36, 'Poitiers', '+33549498073');Dans le cas des créations via l'outil Cassandra CLI, nous constatons qu'il faut réitérer l'appel à la commande autant de fois qu'il y a de valeurs de propriétés à insérer.
Au contraire pour CQL nous nous retrouvons à utiliser à une requête INSERT classique permettant de valuer plusieurs propriétés.
IV-C-2. Interrogation▲
L'interrogation permet d'extraire des lignes à partir d'une famille de colonne.
Cassandra CLI
LIST Persons;
GET Persons['BARON'];
GET Persons['BARON']['firstname'];Deux commandes sont disponibles (list et get). La première est utilisée pour des extractions par paquet. La seconde est particulièrement utilisée pour récupérer unitairement une ligne.
CQLSH
SELECT * FROM cassandrademocql.Persons;La commande SELECT est disponible. Elle permet comme en SQL d'extraire les données en projetant les propriétés voulues.
Autant avec Cassandra CLI que CQL, il est possible de définir des conditions (via WHERE). Nous étudierons en détail dans un troisième article dédié à CQL les limites de l'extraction de données via une requête CQL (problème lié aux index, les limites de la commande…).
IV-C-3. Modification▲
Intéressons-nous maintenant à la commande pour la modification d'une ou plusieurs lignes.
Cassandra CLI
USE cassandrademocql;
SET Persons['BARON']['firstname']=utf8('Keulkeul');CQLSH
UPDATE cassandrademocql.persons SET firstname = 'Keulkeul' WHERE familyname = 'BARON';Pas de grosse surprise concernant ces commandes. J'ai juste constaté que pour modifier une ligne avec Cassandra CLI, j'ai dû préciser le format de la valeur via l'utilisation de UTF8.
IV-C-4. Suppression▲
Finalement la suppression consiste à supprimer une ligne ou une colonne.
Cassandra CLI
DEL Persons['BARON'];CQLSH
DELETE FROM Persons WHERE familyname='BARON';Dans le cas des commandes utilisées, nous supprimons la ligne entière. Nous étudierons dans le troisième article comment effacer des colonnes précises.
V. Outils de supervision▲
Nous présentons dans cette section des outils de supervision disponibles. À cette étape de présentation de Cassandra nous nous focaliserons uniquement sur comment récupérer les informations d'une instance (keyspace, famille de colonnes, statistiques…). Certes utiliser Cassandra sur une instance n'a pas trop de sens puisque celui-ci est bâti pour fonctionner avec plusieurs instances. Toutefois, nous reviendrons dans l'article sur la scalabilité afin de montrer leurs forces sur un véritable cluster.
V-A. nodetool▲
L'utilitaire nodetool est un outil en ligne de commande qui permet de superviser et d'administrer Apache Cassandra. Cet utilitaire est fourni avec la distribution de Cassandra via l'exécutable nodetool.bat depuis le répertoire bin de Cassandra.
Vous pouvez par exemple avoir un état complet d'un cluster, faire un snapshot et donner des statistiques sur des keyspaces et ses familles de colonnes.
V-A-1. Afficher des informations▲
Trois principales options permettent de retourner des informations.
L'option status donne des informations sur les nœuds d'un cluster (état, la capacité des données…).
nodetool -h localhost -p 7199 status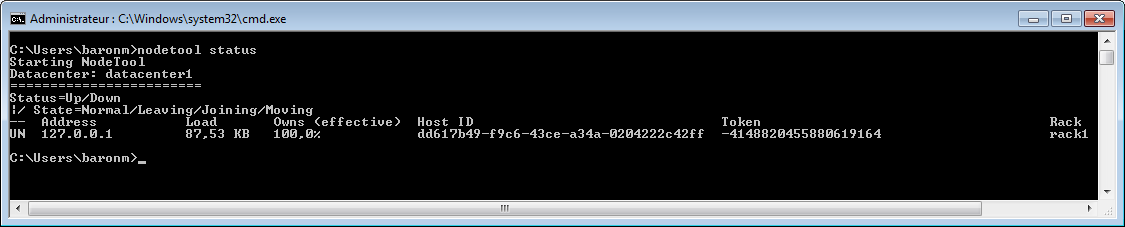
L'option cfstats donne des informations sur les familles de colonnes.
nodetool -h localhost -p 7199 cfstats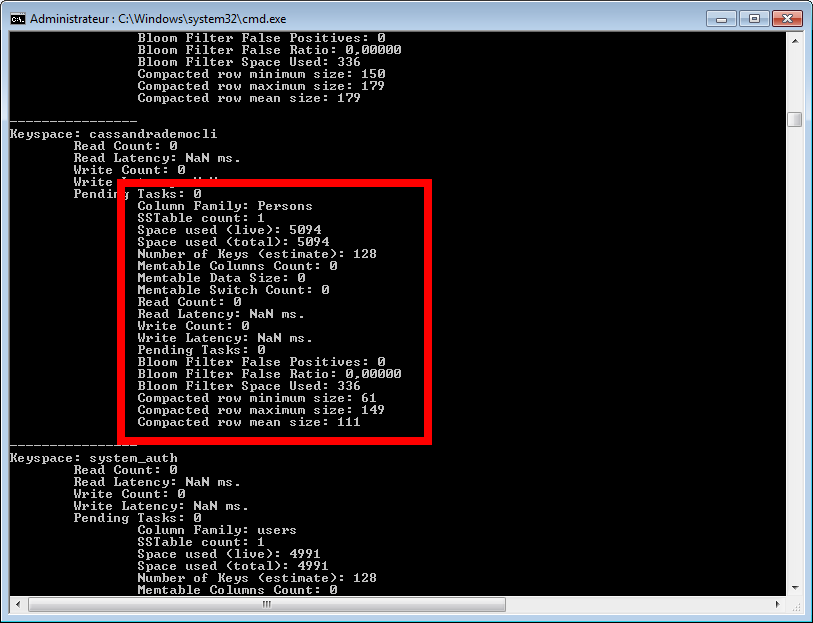
Finalement info donne des informations sur un nœud d'un cluster.
nodetool -h localhost -p 7199 info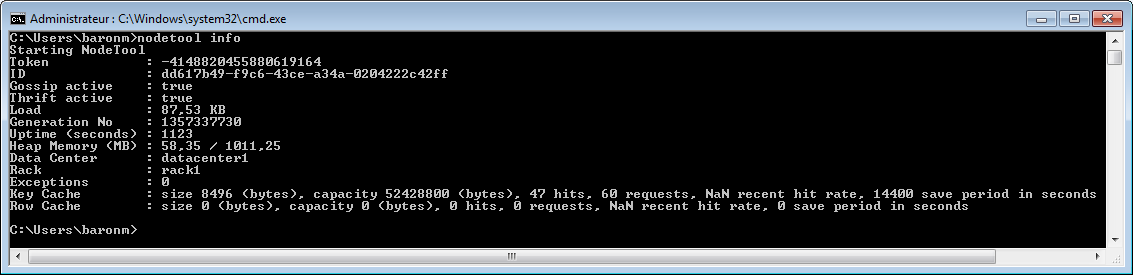
V-A-2. Créer et supprimer un snapshot▲
L'option snapshot permet de faire une sauvegarde explicitement demandée par l'administrateur. Le résultat de la sauvegarde est stocké dans chaque répertoire dédié à une famille de colonnes d'un keyspace donné (<cassandra_data>/data/<keyspace_name>/<column_family_name>/snapshots). Ainsi pour l'exemple traité dans cet article, nous obtiendrons un résultat similaire dans CassandraData/data/cassandrademocql/persons/snapshots/1356865016531 si la commande suivante est exécutée :
nodetool -h localhost -p 7199 snapshot cassandrademocqlL'option p permet de spécifier le port JMX et l'option h permet de désigner l'hôte.
Pour supprimer les snapshots vous pouvez utiliser la commande clearsnapshot.
nodetool -h localhost -p 7199 clearsnapshotV-A-3. Provoquer un flush▲
L'exécution de la commande flush permet d'imprimer la zone mémoire physiquement sur le disque. À noter que lors d'un snapshot cette commande est appelée en premier.
nodetool -h localhost -p 7199 flushV-B. JConsole▲
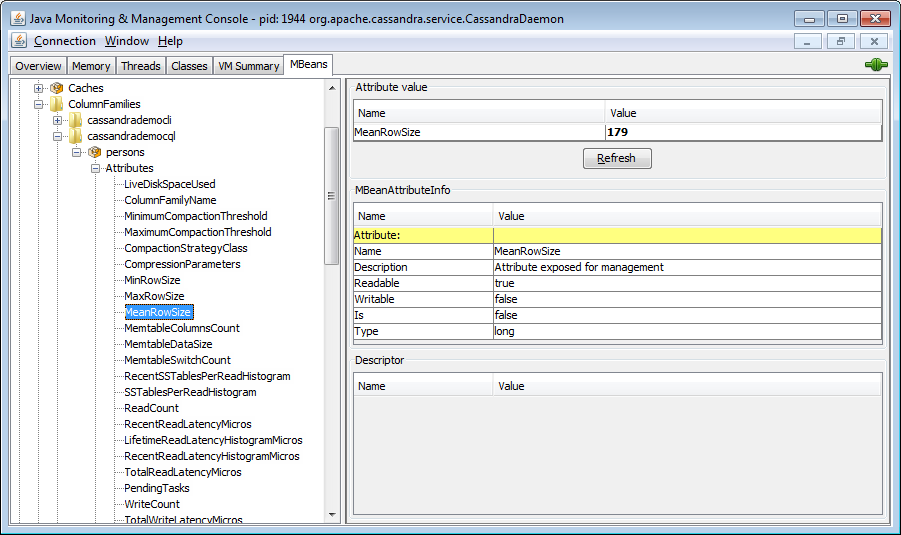
Via l'outil JConsole fourni par la JDK, il est possible de se connecter par l'intermédiaire de JMX. Cet outil n'est pas nouveau dans le monde Java. Il permet de démontrer qu'une instance Cassandra est interrogeable via JMX.
Il vous est donc possible de gérer et de monitorer les nœuds Cassandra. Par exemple sur la figure ci-dessous, nous montrons comment obtenir les informations sur la famille de colonnes Persons.
V-C. OpsCenter▲
OpsCenter est un outil Web de supervision fourni par la société DataStax. L'outil est gratuit dans sa distribution communautaire. Dans sa version Windows, OpsCenter n'est pas disponible unitairement en téléchargement. Il faudra passer par le package Community pour obtenir une version.
OpsCenter fournit tout un ensemble de fonctionnalités pour la gestion d'un cluster (visualisation d'un cluser, métriques…). Nous y reviendrons dans le dernier article de cette série.
Il peut également s'occuper de visualiser les données et fournit des interfaces graphiques pour modifier le schéma (voir capture d'écran ci-dessous)
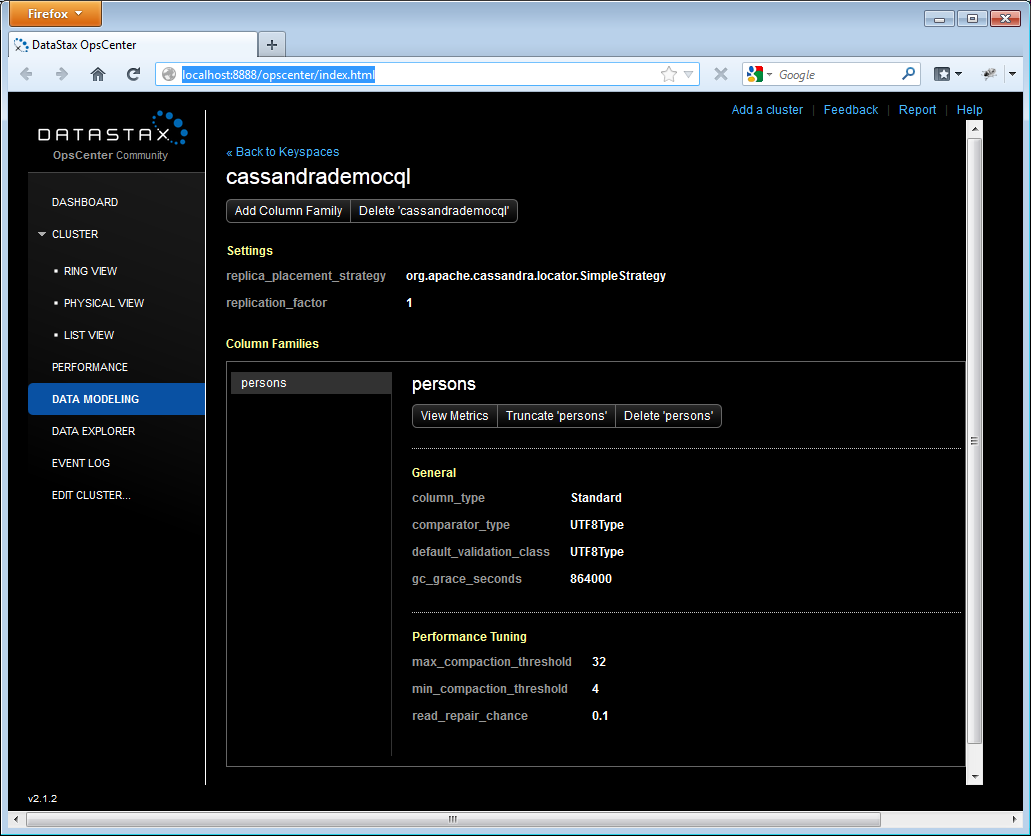
VI. Conclusion, à suivre dans le prochain article▲
Certes, cet article n'est pas révolutionnaire pour une présentation de Cassandra, mais l'objectif visé et avant tout de présenter les concepts-clés, de manipuler un premier modèle et de présenter les outils de supervision. De même vous auriez pu vous attendre à ce que l'article détaille les technologies innovantes de Cassandra (cluster, scalabilité horizontale…), mais ce n'est que le premier article d'une série de cinq.
Dans le prochain article, je présenterai l'étude de cas d'un blog et les besoins auxquels nous devrons répondre. Nous élaborerons ainsi un modèle suivant le schéma proposé par Apache Cassandra en se basant sur les requêtes que nous souhaitons réaliser. Nous implémenterons une couche d'accès aux données (patron de conception DAO) via des API tierces utilisées pour se connecter à Cassandra.
Je tiens à remercier ClaudeLELOUP pour sa relecture orthographique attentive de cet article et Stéphane JEAN mon collègue de l'équipe IDD au laboratoire informatique LIAS/ENSMA de Poitiers pour sa relecture technique et ses précieux conseils.
VII. Références▲
VII-A. Liens anglophones▲
- http://planetcassandra.org/
- https://www.ibm.com/developerworks/library/os-apache-cassandra
- http://techblog.netflix.com/2011/11/benchmarking-cassandra-scalability-on.html
- http://io.typepad.com/glossary.html
- http://www.datastax.com/documentation/cassandra/1.2/webhelp/index.html
- http://www.datastax.com/dev/blog
VII-B. Liens francophones▲
- http://www.betecommechou.com/2009/07/cassandra-le-modele-de-donnees
- https://fr.slideshare.net/jaxio/introduction-cassandra
- http://blog.jetoile.fr/2012/03/petits-retours-sur-cassandra.html
- http://blog.xebia.fr/2010/05/04/nosql-europe-bases-de-donnees-orientees-colonnes-et-cassandra/
- http://lescastcodeurs.com/2012/10/29/les-cast-codeurs-podcast-episode-66-interview-sur-cassandra-deuxieme-partie/
- http://lescastcodeurs.com/2012/10/06/les-cast-codeurs-podcast-episode-65-interview-sur-cassandra-premiere-partie/
